更新: 2013-09-04 17:09:01
生態学のデータ解析 - WinBUGS 雑
- WinBUGS は ベイズ推定 の MCMC 計算につかうソフトウェアです
- とりあえず manual を読んでください: WinBUGS User Manual
- 参照: WinBUGS のインストール, WinBUGS 多変量正規分布, bugs() 関数の返り値, coda 雑, JAGS 雑
[もくじ]
- WinBUGS の内部?
- WinBUGS の sampling 精度の限界?
- 連続なはずなのに「離散化」する事後分布
- ゐんばぐすのおかしなところ
- WinBUGS 使用時の debug
- 「収束がよくない!」ときのちぇっくぽいんと
- 「良くない」BUGS coding の例
WinBUGS の内部?
- WinBUGS による事後分布のサンプリングはかなり巧妙なプログラムなのですが,実際どうなっているのかその詳細は不明です
- WinBUGS は Gibbs sampler と呼ばれていますが,解析的に導出できる事後分布からの Gibbs sampling だけでなく, adaptive rejection sampler (ARS) や slice sampler によるいわば「数値的な」 Gibbs sampling,さらにM-H 法も使われているそうです
- とりあえず manual を読んでください: WinBUGS User Manual
- WinBUGS の乱数発生のしくみ (random number generator) は不明です……かなりしょぼいようです (kubolog2011-12-19)
WinBUGS の sampling 精度の限界?
- 0.001 程度?
- 推定したいパラメーターが説明変数の係数である場合,説明変数の単位を変える (例: 100 cm → 1.0m),あるいは説明変数の標準化をすると収束がよくなることがある
- これは精度限界 (?) 0.001 付近ではパラメーターの値の動きは悪いけれど,0.1 といったスケイルでは比較的よく動いてくれるので
サンプル平均がなんでゼロになるの!? (1) なめらか篇
- 事後分布の中心がゼロとなるはずがない パラメーターのサンプル値の標本平均がゼロとなる場合があります
- これはそのパラメーターの値 (もしくはそのパラメーターを使って作られる値) が 0.001 ぐらいのときに発生する現象のようです
- またこのようなときには,サンプリングの結果はあたかも「連続的な事後分布からランダムサンプルされているように見える」,つまりうまくサンプリングしているように見えます
サンプル平均がなんでゼロになるの!? (2) がたがた篇
- WinBUGS がどのようなときにどの sampler を使っているのかはっきりしませんが,「0.001 きざみで値が増減する」といった現象がいくつかの事例で観察されました
- つまり 0.001 より小さいスケイルでのサンプリングはうまくいかない可能性があります
- これは値そのものが「0.001 ぐらい」というより,「事後分布の幅が 0.001 ぐらい」のときにうまくいかない,ということなのかもしれません (未解明)
- 「どうしてこのパラメーターの事後分布がゼロをまたいでいるんだ?」といった問題が生じた場合は,事後分布の平均・分散がどうなるかを調べると有用な場合があります
- たとえば
glm()などでパラメーターの推定値がとりうる範囲をおおざっぱに調べる - このような場合,(たとえば) 平均値を定義する式全体を定数倍 (例: 0.001 倍)する,といった姑息な「定数倍わざ」をすることで適切な事後分布が得られることがあります
- たとえば
- また階層ベイズモデルの場合,個体差ばらつきパラメーター (ここでは分散
1/tauあるいは分散逆数tau) の無情報事前分布の設定が悪いと「効果のあるはずの説明変数の効果が見えない」といった結果になることがあります.-
tauの無情法事前分布がdgamma(1.0E-3, 1.0E-3)ぐらいだと,「個体差」「ブロック差」といった random effects 的な部分が充分に小さくならない場合があります (応答変数の全分散より小さな1/tauになる必要がある) - このために,応答変数にみられる (微少な) ばらつきがことごとく「個体差」として説明されてしまったりします (すると fixed effect 的な部分による説明がでるまくがない)
- 分散逆数の
tauが充分大きくなれるようにtauの事前分布を十分に無情報化しておく必要があります (例:dgamma(1.0E-6, 1.0E-6)) - しかしこのわざを使うと,分散逆数の収束が遅くなることがあります (いったん大きな値になると,なかなか「帰って」こないなど)
-
連続なはずなのに「離散化」する事後分布
- 「動きの悪いパラメーター」(ばらつきの小さいデータの平均値とか?) の事後分布が離散化することがあります
- 例: 下の図の
bb[9]は 5 個の値のあいだをいったりきたりしているだけ,です (しかし充分に混交はしている)- ある条件のもとでは, 離散 random walk な Metropolis-Hastings 法が使われる?
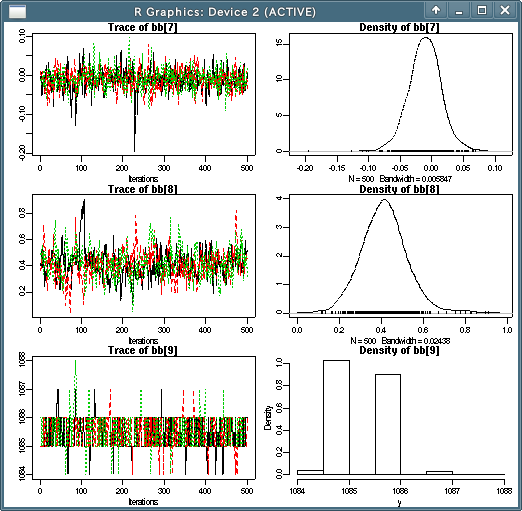
- 例: 下の図の
ゐんばぐすのおかしなところ
- WinBUGS に読みこませるファイル (BUGS 言語でモデルを定義したファイルなど) のフルパス名に注意する必要があります.
- フルパス名に日本語文字が含まれると「ファイルが見つからん」とエラーをだす
- ゐんどーづなど「デスクトップ」上なんかはダメ
- 同じくゐんどーづ上だと「マイドキュメント」は問題ない (ホントのフォルダ名が "My documents" だから)
- フルパス名が ある程度以上長い とまったく動作しなくなる (ゐんばぐすは起動するけどまったく動かない)
- もっと「浅い」ディレクトリで作業する必要があります
- フルパス名に日本語文字が含まれると「ファイルが見つからん」とエラーをだす
WinBUGS 使用時の debug
- けっこう難しいです
- エラー表示をよくみる
- しかし「Trap 窓」だされても何が原因なのかよくわからなかったり
- Small Data Scientist Memorandum さんの WinBUGSの困ったTrapと対策集(募集中) をよく読みましょう!!
- R2WinBUGS で WinBUGS を呼びだしたときに WinBUGS 内でエラーが出ることがある
-
bugs()で WinBUGS を呼ぶときに debug = TRUE とつけておくと WinBUGS のどこでエラーが生じたかわかる - ありそうなエラーの種類:
- BUGS コードで書かれた
model{...} がまちがっている - 必要なデータが WinBUGS にわたされていない
- WinBUGS に (計算で使わない) よけいなデータをわたした
- 初期値を設定できるパラメーターには全部初期値を設定する!
- 可能であれば,パラメーターの初期値は「それっぽい」値を設定する
- などなど
- BUGS コードで書かれた
-
「収束がよくない!」ときのちぇっくぽいんと
- Small Data Scientist Memorandum さんの WinBUGSの困ったTrapと対策集(募集中) をよく読みましょう!!
- モデルがよくない・まちがっている
- いちばんよくある事例
- 観測データにトンでもない「外れ値」みたいなものが含まれている
- そしてそれがうまくモデリングできていない
- パラメーターの初期値がよくない
- 「もっともらしい」値を与えてやる必要あり
- それ以前に,初期値を設定できるパラメーターには全部初期値を設定する!
- 「もっともらしい」値を与えてやる必要あり
- MCMC 計算の step 数が少なすぎる
- burn in, sampling のどちらかもしくはその両方において
- 「良くない」 BUGS coding
- 下の項を参照
- WinBUGS では説明変数 (連続値) を中央化すると収束・混交が格段によくなる場合があります
- ただし説明変数が factor (を離散値化したもの) の場合だと,中央化するとかえって遅くなることがあります
「良くない」BUGS coding の例
- ここでは BUGS code 中のパラメーターを
p1, p2, ...と表記する -
p1/p2といった形式のパラメーターどうしの割算 がふくまれている-
p1*p2のかけ算もあまり良くないようだ - パラメーターに関する非線形なモデルは可能なかぎり回避したほうがよさそう
-
-
p1 + p2となっているときに……-
p1もしくはp2どちらかの値が大であればそれでよい,という状況であるならば -
p1とp2はいつまでたっても収束しない可能性がある - あるいは説明変数の設定にしくじっている場合
- 全個体の説明変数が同じ値にになっている (例: 全個体が処理 A,など)
-
- 再帰的な deterministic node (
<-) があると計算は劇的に遅くなる- 例1: 時系列モデルで
x[t] <- x[t - 1] ...とするとむちゃくちゃに収束がおそくなる (recursive な配列要素間の参照が含まれるので) - 対策: stochastic node (
~) に置きかえられないか検討してみる
- 例1: 時系列モデルで
-
inprod(x[i,],exp(z[i,]))といったinprod(,)の中にexp()があるような書きかたはダメなようで Trap 窓が出る.あらかじめexp.z[i,j]<-exp(z[i,j])といった変数を準備しておけば,この問題は回避できるもよう. - これは BUG coding の問題ではなく「どの値をサンプリングするか」という問題なのですが……「なんでもかんでも記録しておく」と処理が遅くなる場合があります.たとえば,MCMC サンプリングにおいて各ステップごとに数万個のパラメーターを「記録」させようとすると,各ステップあるいはサンプリング終了後の処理が遅くなります.どのパラメーターの値を記録する必要があるのか,よく吟味してください.