更新: 2018-08-15 17:10:25
生態学のデータ解析 - 時系列データ解析
- 時系列データの統計モデリングについて
[もくじ]
R で時系列データ解析

- RjpWiki 内の 時系列データオブジェクト に関する情報
library(KFAS)
一般化状態空間モデルをあつかう library(sspir)
ちょっとメモ
- 時系列事前チェック
- Stanで気温変動のフィッティング
- Pytnonによる時系列分析の基礎
- O-U過程、定常
- 時系列分析(ARIMAモデル)の機能とその活用
- ill-identified さんの KFAS 解説
- 単位根(Wikipedia)
- 回帰分析で適切な方法を使わないとどうなるか (時系列編) ill-identified さん
- http://ill-identified.hatenablog.com/entry/2015/05/11/221645
- http://ill-identified.hatenablog.com/archive
- http://togetter.com/li/939366 こんなグラフがあって「XX時には野生型と変異体で差があります」を言いたいときに
- 時系列モデルと AIC https://twitter.com/hankagosa/status/976630038488469504
- 二階差分の状態空間モデル… (kosugitti さん)
- なぜ状態空間モデルを使うのか Logics of Blue (馬場さん)
現代的な時系列データの統計モデルは何をやっているのか?
現代的な時系列モデリングというと (一般化) 状態空間モデルということになるのでしょう. これは「内部」状態 (status space) と観測値が分離されたモデルです:
- 直接観測できないいわば「内部」状態の時間変化: x[t] <- x- 1 + u[t]
- 状態が観測できる量を決める: y[t] <- x[t] + v[t]
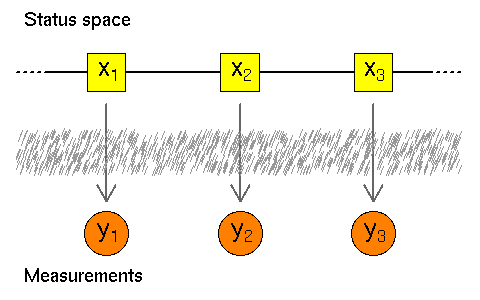
このときに「観測状態の変化 u[t] と測定値のばらつき v[t] はどうして別々に推定可能なのか? 直感的な説明は?」 といった質問をされました.
そのときに, 私が思いついた直感的なハナシというのは次のようなものです.
結局,この問題であつかうデータを図として描くと, 横軸に時間 (time) t でタテ軸に観測値 y[t] の点々がぽちぽちとプロットされることになります. (一般化) 状態空間モデルで推定したことは何か, というとこれらの観測値の点々に対して「できるだけなめらかな曲線を描け」 というものです.
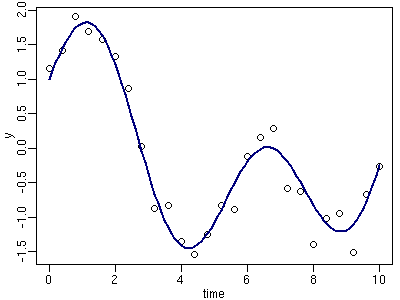
ただし,このときに,
- 曲線はできるだけなめらかにしろ: 各時点で好き勝手な値はとらずにできるだけ「前後」にあわせるようにしろ
- 点々にできるだけあわせろ: たとえば「観測誤差」が正規分布にしたがうのであれば,曲線と点々の二乗誤差を最小にしろ
といった矛盾するふたつの制約をつけられているわけです. つまり,曲線をできるだけなめらかにすると観測値とのずれである二乗誤差が大きくなり, いっぽうで二乗誤差を小さくしようとすると曲線ががくがくぎざぎざになります.
状態空間モデルでは観測とのずれだけでなく, 曲線のなめらかさも正規分布など確率分布で表現されます. したがって, この統計モデル全体の尤度ができるだけ高くすることで 上の二条件のあいだの妥協点を見出すことができるわけです. つまり,尤度の観点から「なめらかさ」と「あてはまり」 のバランスをとっているのです.
- 参照: ウミガメモデル
- このあたり空間統計モデルも同じように考えます (参照: 例/car.normal())