Backup()
&
Restore()
が必要
unused
パラメーターを指定を指定できるようにしてみたり.
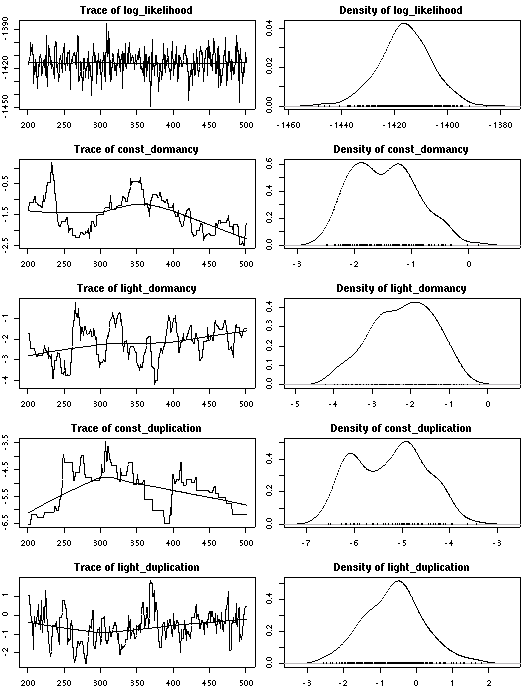
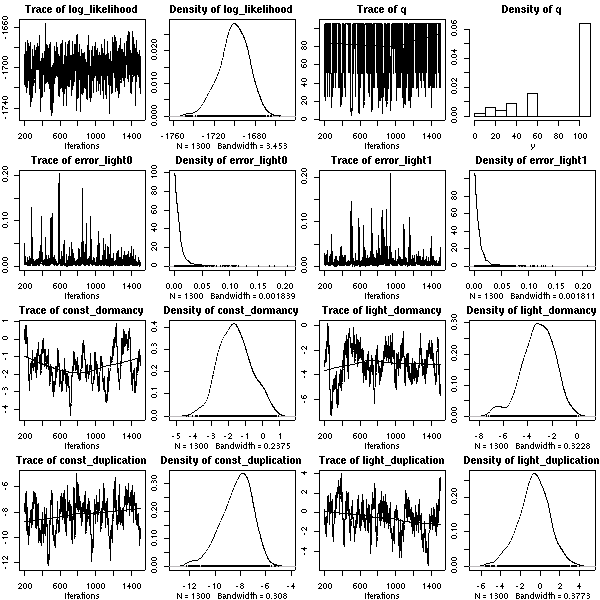
library(coda)
で作図してみる.
10 step ごとのサンプリング結果.
これは「全 22 樹種に共通する部分」.
個体の観測データは
「全体共通部分」 + 「樹種特性」 + 「個体特性」
で説明される
(樹種差・個体差はこのさらに下に).
ふーむ,
妥当なかんぢではあるんだが
……
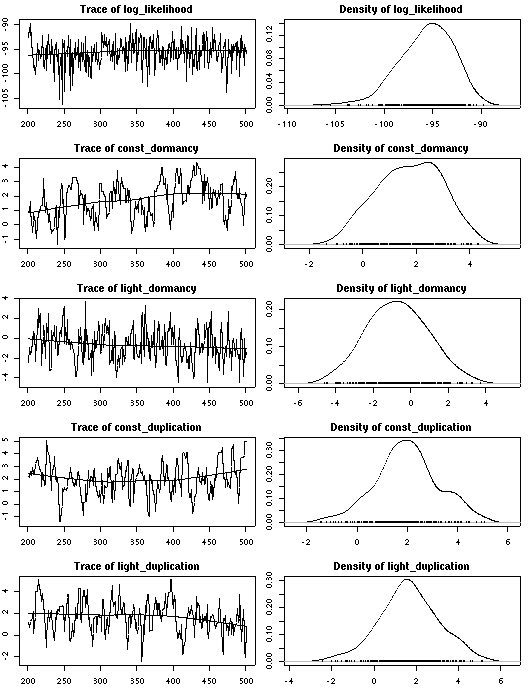
A17
番個体の特性をあらわすパラメーターども.
やはりこのサンプル数だとほとんど「個性」は出ない.
しかし二度伸び (duplication? duplex? elongation)
はゼロからずれぎみ.
ftable
にいれてしまう,
というもの.
これは巧妙な方法に思えるんだが
……
いかんせん ftable クラスのメソッドがへぼくて,
write.table()
などがうまく動作してないようだ.
sink(...)
すればテキスト出力できるんだけど
……
庄山さんに聞くと,
何やら
PC-ORD
とかいったソフトウェアで TWINSPAN 計算やりたい
(このあたり十年一日のごとく進歩なく
統計学的根拠のよくわからん計算やってていいのか,
という気もするんだけど),
とやらで,
マニュアルによると ftable の
sink() 出力そのままではダメ,
とわかった.
「植物種+階層」と「場所」の二次元の表じゃなきゃいかんそーで.
matrix
を作り,
全要素をゼロとする
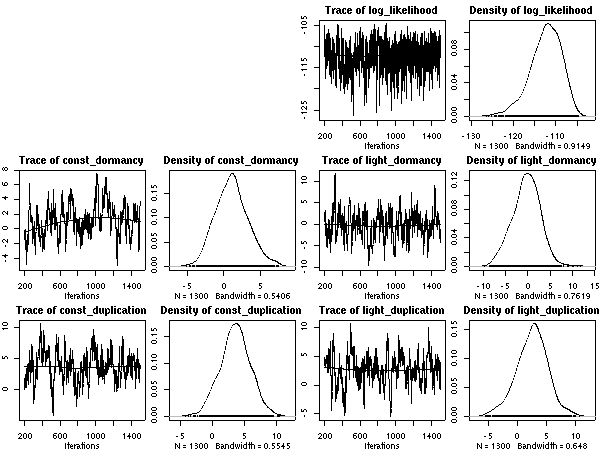
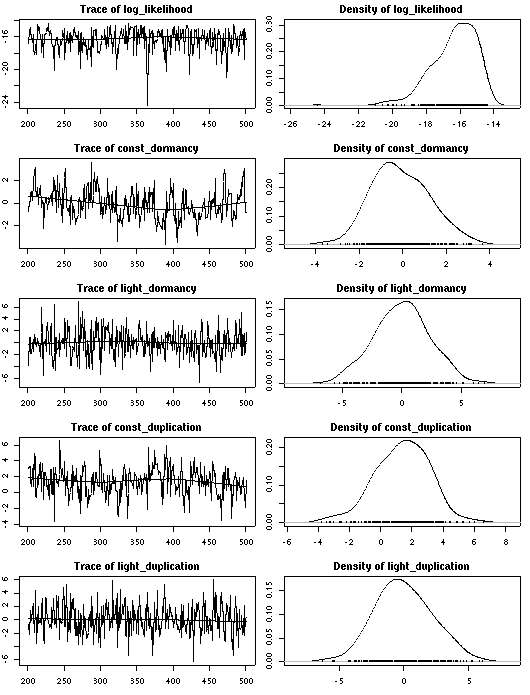
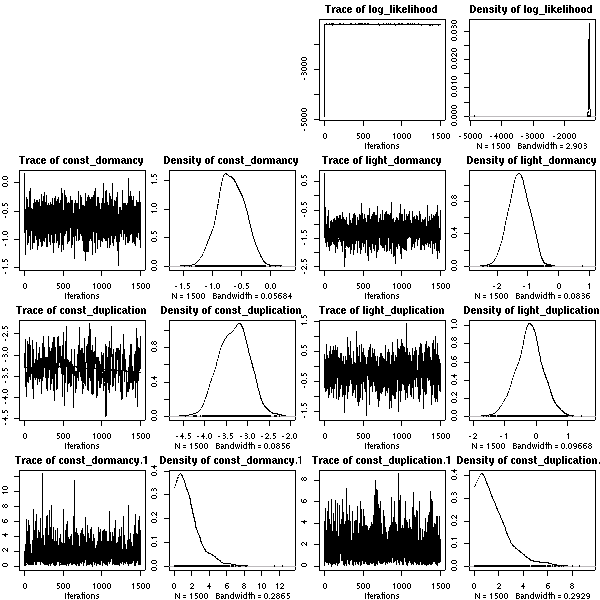
A17 番).
A17
のパラメーター分布がゼロを中心とするものになっている,
とわかる.
ぢつに妥当な結果だと思う.
というのも,
これは
「22 樹種 105 個体の標本しかないのに,
樹種差や個体差を推定するのは無理」
ということをあらわしているからだ.
Bayes 推定ってかなりマトモかも,
という気がしてきた.
legend()
置くのはどうしたらよいか?
RjpWiki
内の
実例紹介
が参考になる.
par(xpd = TRUE)
とマージン設定
(par(mar = c(...))),
さらに
par()$usr[...]
による座標指定のこんびねいしょんワザ,
か.
@ISA 使うあれ)
を濫用してデータ構造の大幅な粛正.
基底クラスに指定されたのは
……
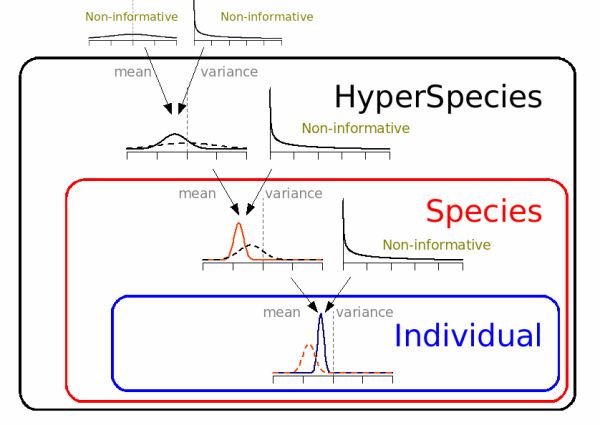
ParameterBase:
推定すべき値と事前分布をもつクラス.
ここから
ParameterGaussian
と
HyperparameterGamma
が派生する.
OwnerParameter:
ParameterBase 派生クラスをもち,
あるいは観測データなども持つ.
Metropolis-Hastings 法における尤度計算の奴隷.
ここから
OwnerFixedEffects
と
PriorGaussian
(hyperprior の奴隷なので)
が派生する.
OwnerFixedEffects:
二段階の単継承によってこれも基底クラスとなっている.
派生するのは
TreeP (樹木個体)
と SpcP (樹種)
と HyperspcP (ちょー樹種).
MCMCpack
とかで実装しようとしたらかなり苦闘しそうな.
あるいは Metropolis sampler やめて Gibbs sampler
にしたら多少はマシになるとか?
うーむ
……
perl -d プログラム名
とゆー Perl debugger 使ってしまいましたよ
(perldoc perldebtut 参照).
dgamma(x, shape = 1, scale)
すなわち指数分布にしている.
で,
この hypeprior のカタチを支配する hyperparameter
である scale
をどう定めるべきか,
なんだが
……
線形予測子は logit な世界をふらふらしてるわけで,
いやはやどうしたもんだか.
とりあえず 10 とか 20 ぐらい?
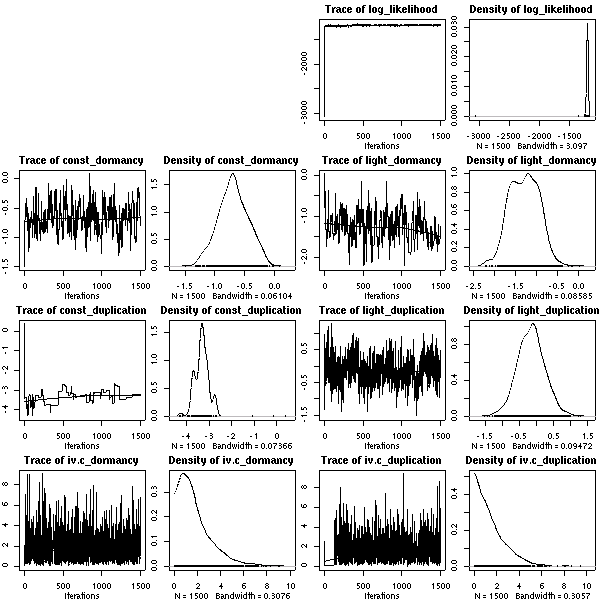
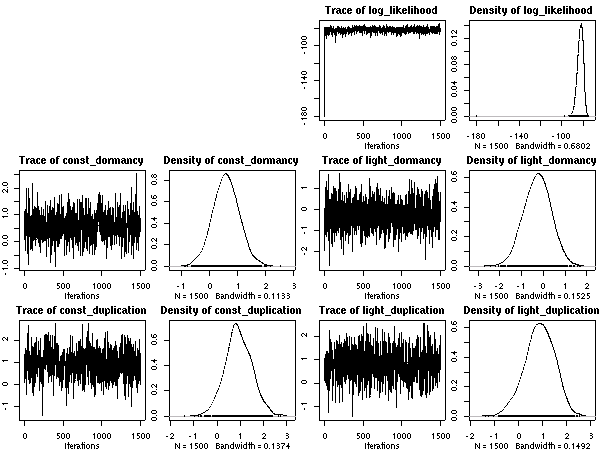
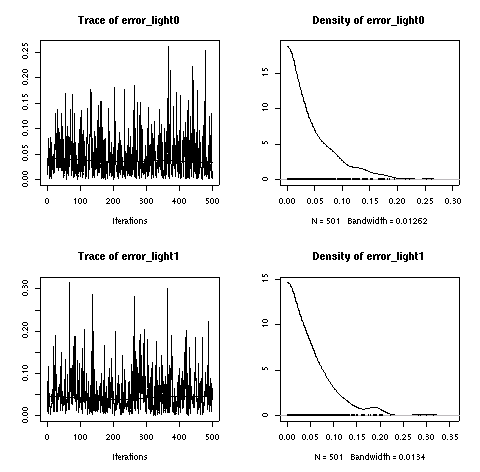
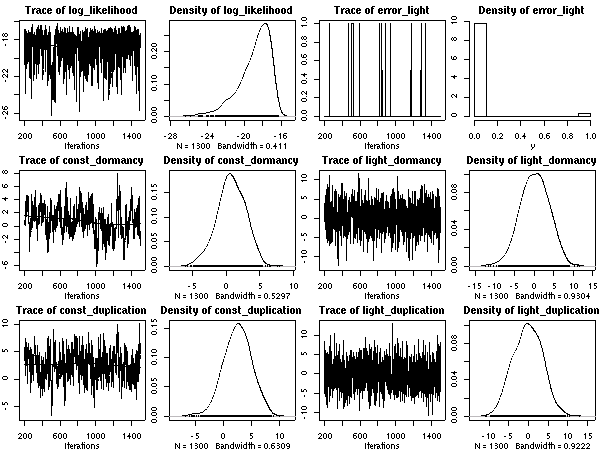
A17 番).
やはりこのサイズのデータでは「個体差」は見えない.
そして
(あたりまえのことながら)
こちらも variance がマシになっている.
library(coda)
の heidel.diag()
という一番安直そうな収束診断にほうりこんでるだけ.
今日しめした図の場合 Heidel 的には OK
(昨日のもだいたい問題なし)
ということになっている.
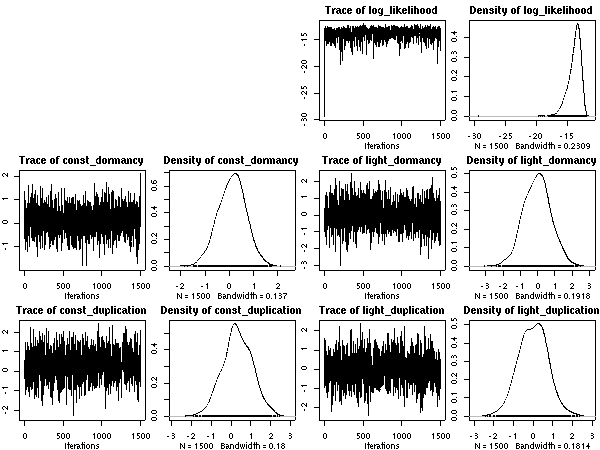
dgamma(x, 1, 10)
にした
(昨晩の計算では
dgamma(x, 1, 5)).
これぐらいの変更では事後分布どものカタチはほとんど変わらない,
と確認できた.
よしよし.
library(coda)
も悪くないんだけど
……
事後分布を全部
みたいときにはどうしたらよいだろう.
library(grid)
の活用が有効だろう
……
ということで
grid 事始
など読みつつ勉強する.
これって,
ふつーの R の library(graphics)
とはけっこう違うね.
状態を Push & Pop して階層的な図を作る,
と.
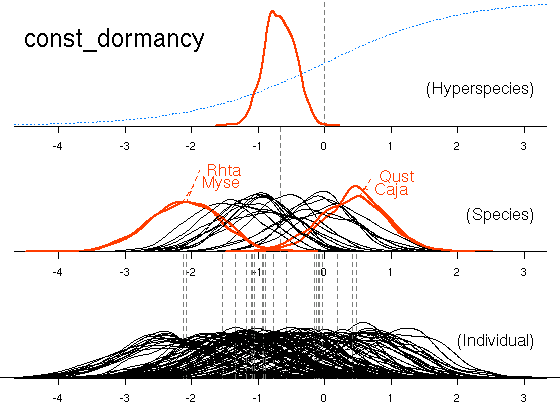
Rhta)
とタイミンタチバナ (Myse)
は寝つきが悪く,
逆に
ウラジロガシ (Qust)
とツバキ (Caja)
は眠りこみやすい.
data.frame()
まわりは苦闘します.
library(grid) グラフィック環境ぷろぐらみんぐのつづき.
grid
では「わく (viewport())」を押しこむ (push)・ぬける (pop)
を繰りかえして「階層的」に作図していく
(RjpWiki
内の
grid 事始
も参照).
grid.newpage() # 新しい grid page
pushViewport(viewport( # 一番外のわくを準備,これは 2x2 に分割されている
x = 0.5, y = 0.5,
h = 1, w = 1,
layout = grid.layout(2, 2)
))
for (i in 1:nrow(df.grid)) { # 2x2 のわくのひとつひとつに
plot.each( # 2x1 に分割された図を押しこんでいく
name.parameter = p.fixed[i],
col = df.grid[i, 1],
row = df.grid[i, 2]
) # (注: ``plot.each(...)'' は久保の自作関数)
}
popViewport() # 一番外のわくからぬける
これを実行すると,
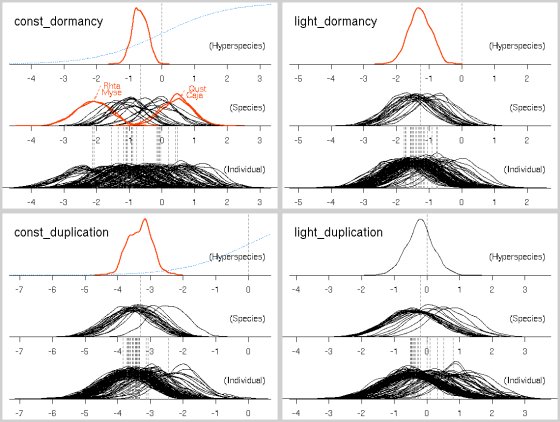
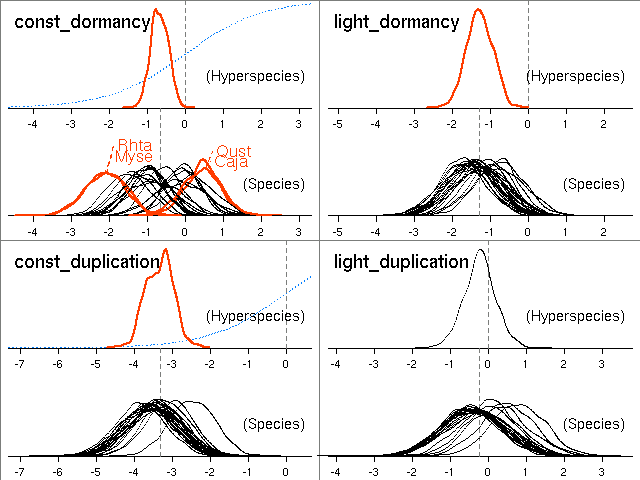
たとえば下のような図がえられる
(昨日の 2x2 図は ImageMagick
の montage コマンドではりあわせたもの).
車はすぐに止まれない
アタマはすぐにきりかえられない



