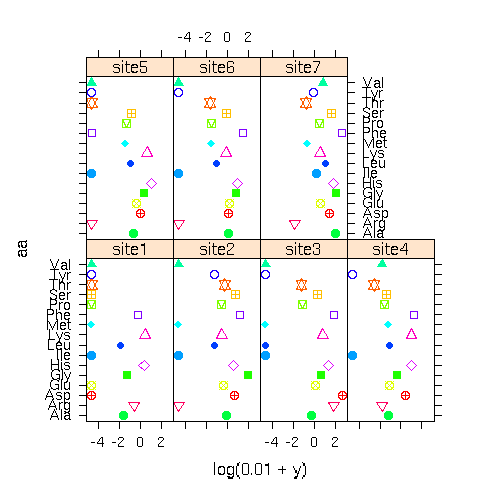
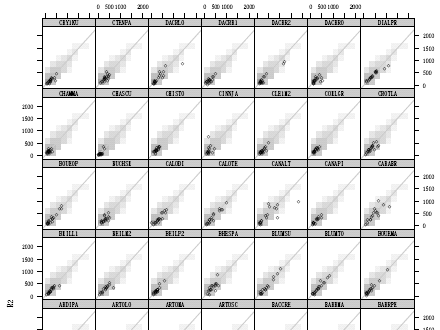
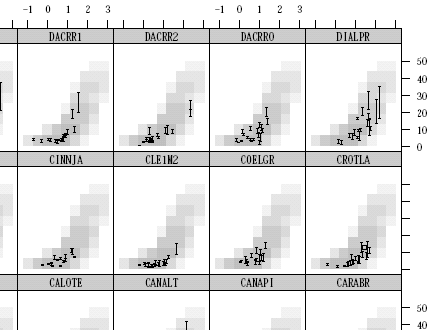
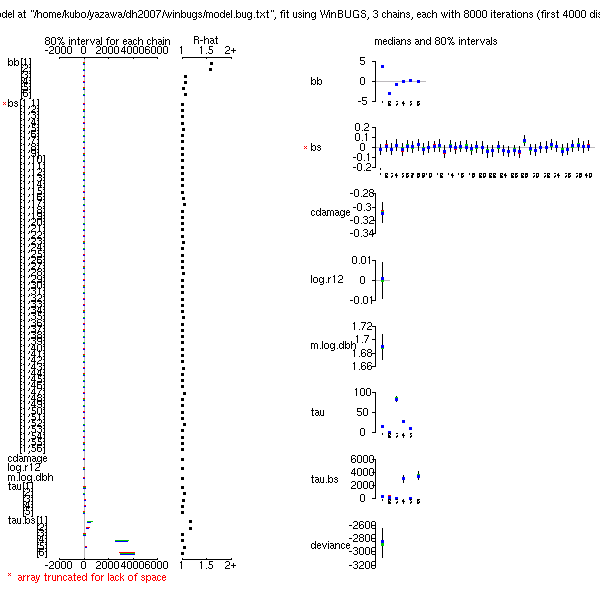
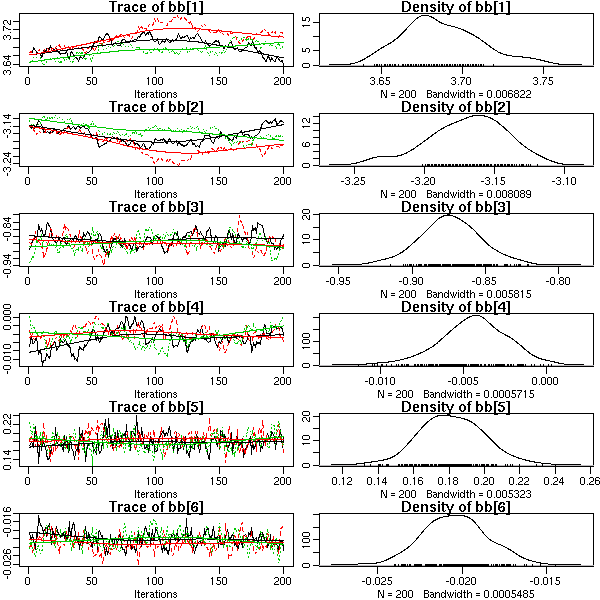
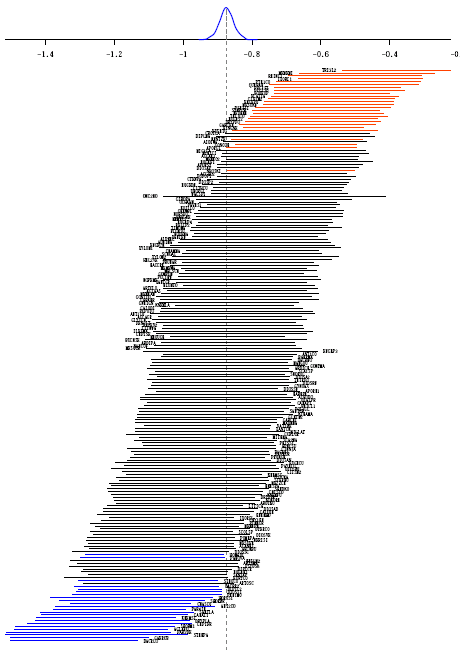
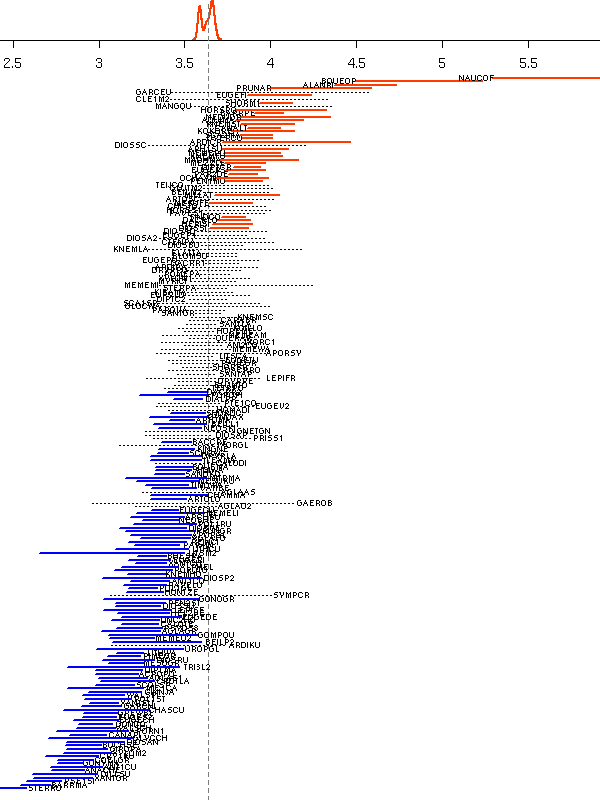
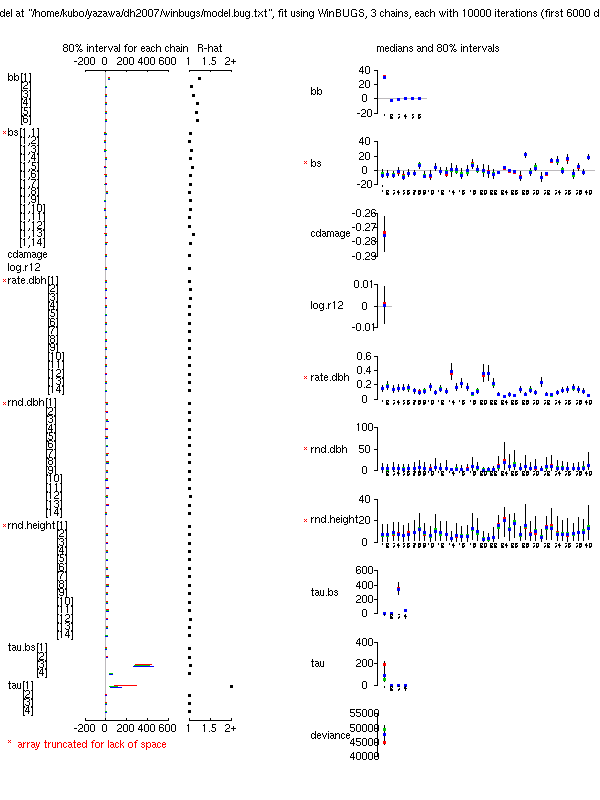
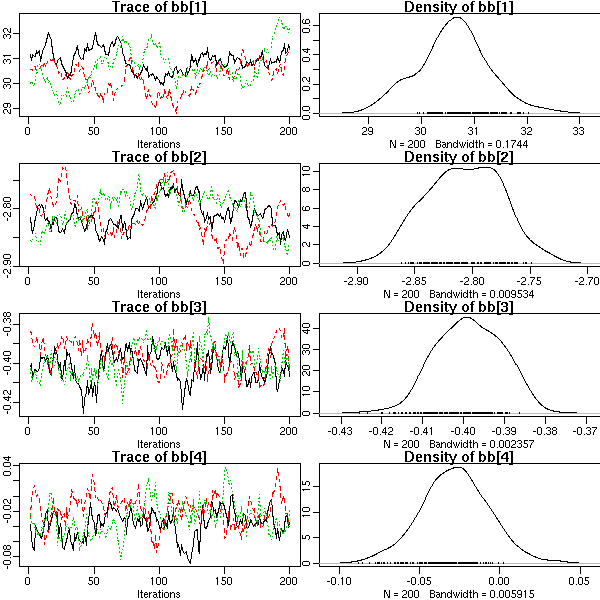
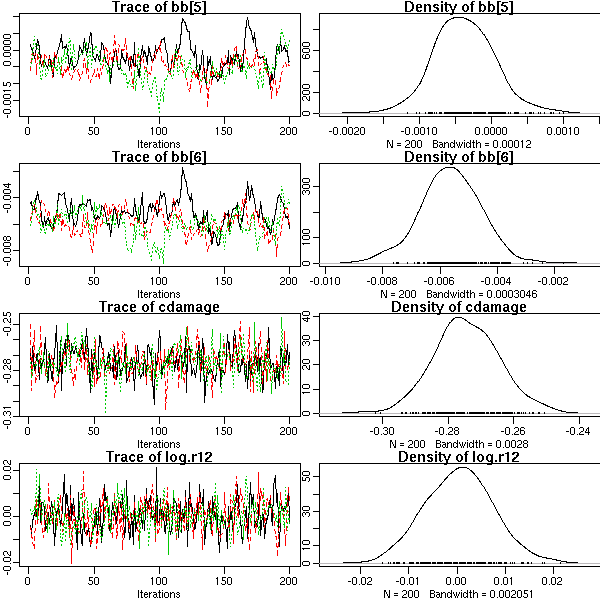
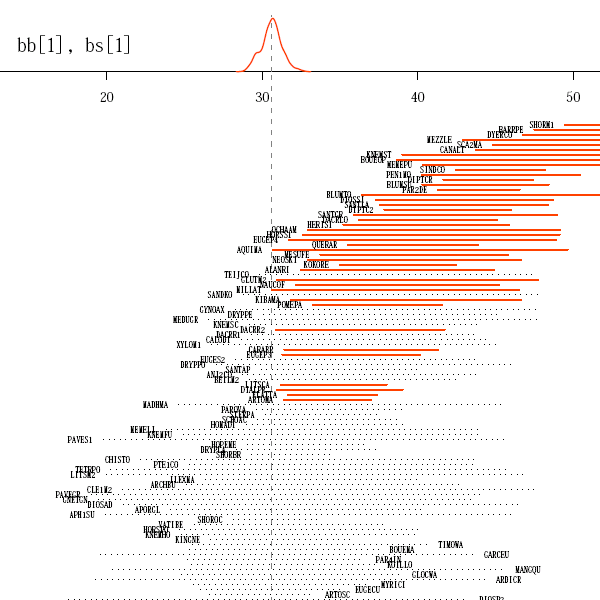
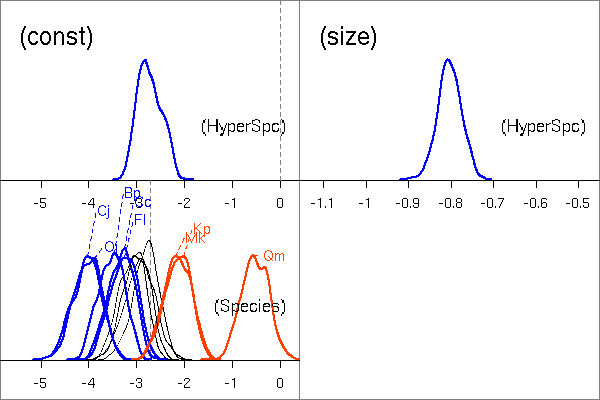
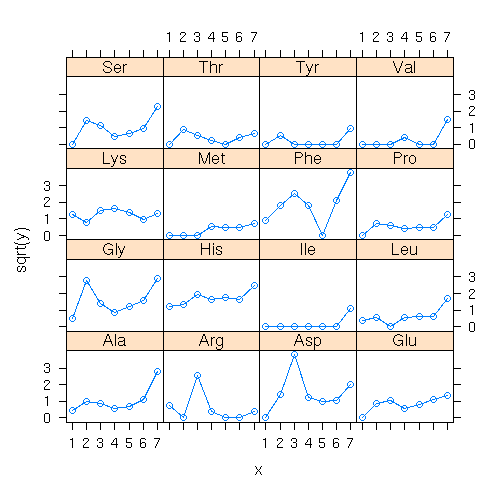
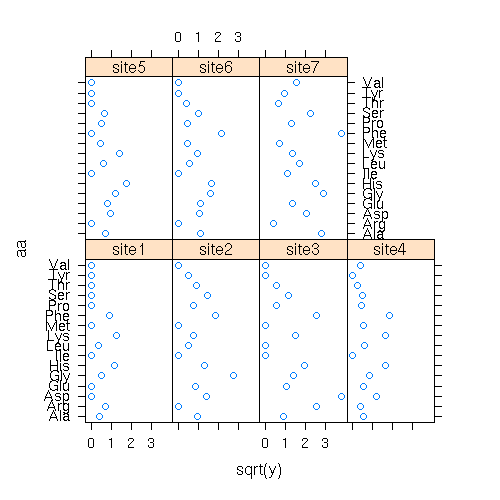
library(lattice)
の xyplot(y ~ x | group, ...)
してみる.
... Whenever you perform some (traditional) multivariate analysis, you are forced to analyse data subjectively rather than objectively. ...とはいえ, もうしばらく R とかで計算したり作図をつづけてみるといろいろ勉強になって 論文の解読なんかも改善されますよ, とニセ教育者的 interface でもって 当方の時間かせぎの意図をごまかしてみた次第.
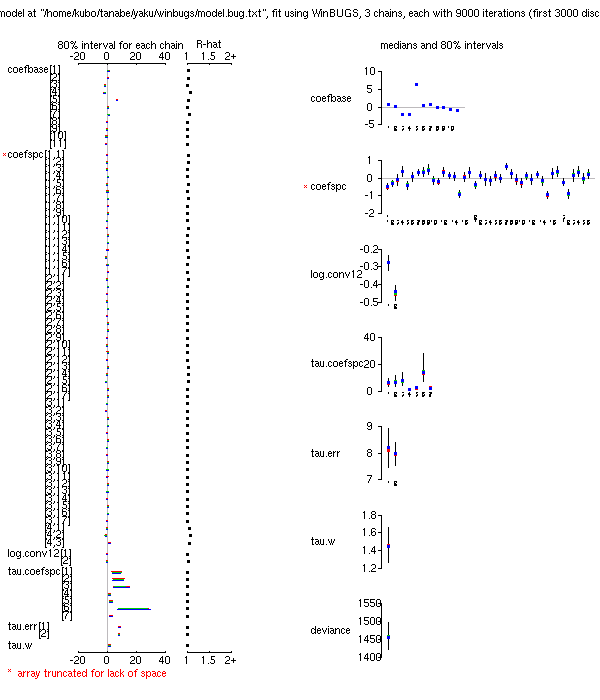
glm(..., family = poisson)
だの
glm.nb(...)
であつかう問題についての解説.
- せめてストレッチぐらいは ……
- 朝 (0810): 米麦 0.6 合. ジャガイモ・タマネギ・ニンジン・ピーマン・鶏肉のカレー.
- 昼 (1320): 研究室お茶部屋. 食パン. ジャガイモ・タマネギ・ニンジン・ピーマン・鶏肉のカレー.
- 晩 (2000): 北 13 西 3 のごはんやデンスケ. カレイの煮つけ.