ぎょーむ日誌 2007-09-(01-10)
2007 年 09 月 01 日 (土)
-
0830 起床.
朝飯.
コーヒー.
怠業.
-
1030 自宅発.
晴.
1050 クラーク会館 1F の
理髪店
着.
しばらく待つ.
ThinkPad で ECOAS プランクトンデータひねくる.
散髪
(前回は 7/7
か)
に 50 分ちょい.
1155 研究室着.
-
web server 機 hosho の backup 用内蔵 HDD の交換作業.
1205 server 停止.
ちょっと入れ換えにてこずって 1219 運転再開.
いままでとは異なり
hda: Maxtor 4D040H2, ATA DISK drive
hdb: ST3402111A, ATA DISK drive
hdc: MATSHITA CR-594, ATAPI CD/DVD-ROM drive
ide0 at 0x1f0-0x1f7,0x3f6 on irq 14
ide1 at 0x170-0x177,0x376 on irq 15
hda: attached ide-disk driver.
hda: host protected area => 1
hda: 80043264 sectors (40982 MB) w/2048KiB Cache, CHS=4982/255/63, UDMA(100)
hdb: attached ide-disk driver.
hdb: host protected area => 1
hdb: 78165360 sectors (40021 MB) w/2048KiB Cache, CHS=4865/255/63, UDMA(100)
hdc: attached ide-cdrom driver.
hdc: ATAPI 48X CD-ROM drive, 128kB Cache, UDMA(33)
Uniform CD-ROM driver Revision: 3.12
というふうになった
(今までは /dev/hdc が二番目の HDD だった).
-
今回こわれた HDD はいつ導入されたのか
……
と調べてみると,
驚くべきことに
昨年の大晦日
だった.
しかも今回と同じく Seagate Barracuda 7200.9
(ただし前回は 80GB,
今回は 40GB).
なンでこんなに早く壊れたのかな?
じつは壊れてなくて,
MBR をいじったり (今回やりなおした)
ケイブル配線の問題だったのかしらん?
そういうアヤしげな記述がぎょーむ日誌にあるよな
……
-
さて,
とりあえず新しく追加された HDD
/dev/hdb
を利用する準備だが
……
えーい,
それ以前の問題として,
じつにおそるべきことにこの server
はきちんと Vine Linux 4.1 化されてない,
と判明した.
/etc/apt/sources.list
をきちんと書き換えて
sudo apt-get install apt
その他で 4.1 化する.
いやはや,
よくもまあ今まで大過なく動作してたもんだ
……
-
待ち時間にいろいろ調べてみる.
ふーむ,
Vine Linux 4.1 から
/etc/fstab
の mount は非推奨になってしまって,
gnome-mount
使えとか書いてあるな
……
gnome-mount -t -d /dev/cdrom
gnome-umount -t -d /dev/cdrom
これらは X を起動してない状況でも使える.
-
apache2
入れ換えたら /etc/apache2/conf/httpd.conf
の読みこみでエラーがでた.
LodeModule
まわりがいろいろと変わっているようなので,
httpd.conf.rpmnew
のそれをコピーする.
これで正常にうごいた.
-
1320 研究室発.
買いもの.
1340 帰宅.
昼飯.
怠業.
ちょっとうんどう.
体重 68.8 kg.
-
そしてまた怠業してたら,
いつのまにか日没時刻.
晩飯.
-
[今日の運動]
-
腹筋運動 30 ×
3 回.
腕立ふせ 10 ×
3 回.
スクワット 100 回.
-
[今日の食卓]
- 朝 (0920):
米麦 0.5 合.
キャベツ・ニンジン・タマネギ・キュウリのサラダ.
ミディトマト.
- 昼 (1430):
ぱん吉のトマト・バジルパン.
キャベツ・ニンジン・タマネギ・キュウリのサラダ.
- 晩 (1930):
スパゲッティー.
ピーマン・タマネギ・シイタケ・トマトのソース.
キャベツ・ニンジン・タマネギ・キュウリのサラダ.
2007 年 09 月 02 日 (日)
-
0810 起床.
朝飯.
コーヒー.
1015 自宅発.
曇.
1030 研究室着.
-
ECOAS プランクトンデータ解析.
占部さんからいろいろいと教えていただいたことを wiki
上にまとめていく.
ECOAS 用はなんとなく PukiWiki にしている
(2005 年に設置).
-
そしてまたいろいろと作図.
緯度ってほとんど関係なさそうな.
ハナシが単純化できるからそれでいいんだけど.
こういう図なんかも wiki にはりつけていく.
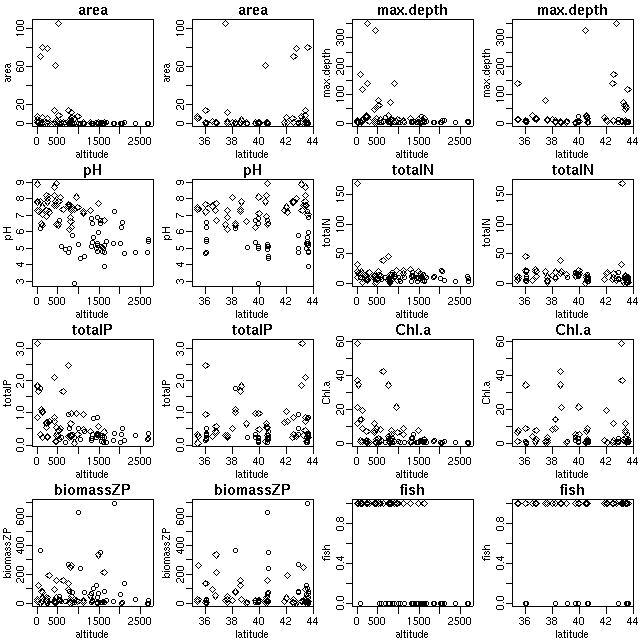
-
標高が高くなると pH が低くなる (酸性になる).
よくわからんのだけど,
同じ標高であっても pH が低いとサカナが住まない?
というか,
そもそも湖沼の pH がどのように決まるのかよくわからん.
-
全窒素が一ヶ所だけ突出して高い池 (北海道内の標高ゼロ付近) があったので,
「データ入力まちがいかしらん?」
と思って
head(d[order(d$totalN, decreasing = T),])
してみると
site site.name year date latitude longitude altitude area max.depth pH totalN
25 25 茨戸湖 2003 37485 43.176 E141 21.520 5 0.66 7.1 7.30 167.559
56 56 諏訪湖 2004 37491 36.049 E138 05.003 755 13.30 5.9 7.65 45.786
40 40 魚取沼 2003 37502 38.637 E140 33.496 625 0.01 7.0 7.35 39.033
27 27 塘路湖 2003 37487 43.144 E144 31.945 5 6.37 6.6 8.88 31.846
47 47 西の湖 2004 37462 36.743 E139 23.810 1295 0.17 16.8 7.30 24.563
7 7 大沼 2005 37458 39.984 E140 47,976 944 0.04 5.6 8.10 22.809
となった.
「茨戸湖」
ってどこよ?
と思ったらここ札幌市北区の
北のはずれ
のよーで
……
この
「ばらとこ」
と読むらしい三日月湖は全リンも全 86 サイト中もっとも高い.
そんなに汚いところなのか?
すぐ近くに下水処理場や道央新道あるからなのかな.
-
このあたりで昼飯.
-
ちょっと server 機の円盤ぎょーむ.
/dev/hda
の現状はこう
$ df -h
ファイルシステム サイズ 使用 残り 使用% マウント位置
/dev/hda1 19G 1.1G 17G 6% /
/dev/hda3 19G 7.2G 11G 41% /home
none 89M 0 89M 0% /dev/shm
なので sudo /sbin/fdisk /dev/hdb
で
Disk /dev/hdb: 40.0 GB, 40020664320 bytes
255 heads, 63 sectors/track, 4865 cylinders
Units = シリンダ数 of 16065 * 512 = 8225280 bytes
デバイス Boot Start End Blocks Id System
/dev/hdb1 1 487 3911796 83 Linux
/dev/hdb2 488 519 257040 82 Linux swap / Solaris
/dev/hdb3 520 4865 34909245 83 Linux
と切ってみる.
$ sudo /sbin/mkfs.ext3 /dev/hdb1
$ sudo /sbin/mkfs.ext3 /dev/hdb3
$ sudo /sbin/mkswap /dev/hdb2
-
これで旧来の
mount
は使えるんだけど,
gnome-mount
使おうとすると
(これは Vine Linux 4.1 における新しい
おススめわざ
とのこと),
segmentation fault
になってしまう.
-
いったん
sudo /sbin/telinit 1
してから exit で run level を 3 にもどす.
HAL だの何だのややこしー daemon が動いているので
……
これでエラーが
** (gnome-mount:30751): WARNING **: Mount failed for
/org/freedesktop/Hal/devices/volume_uuid_5b9c491d_a97b_43a1_98db_911c2da3b88e
org.freedesktop.Hal.Device.Volume.PermissionDenied : Device has
volume.ignore set to TRUE. Refusing to mount.
なる奇妙なモノに変わった.
-
ネット上のあれこれを参考にして,
/usr/share/hal/fdi/policy/10osvendor/99-storage-policy-fixed.fdi
の
<merge key="volume.ignore" type="bool">true</merge>
内を false
にして sudo /etc/init.d/haldaemon restart
したら
$ sudo gnome-mount -t -d /dev/hdb1
gnome-mount 0.4
Mounted /dev/hdb1 at "/media/disk"
$ sudo gnome-mount -t -d /dev/hdb3
gnome-mount 0.4
Mounted /dev/hdb3 at "/media/disk-1"
となった.
うーむ,
こんなんでいいのか?
unmount はこんなかんぢで.
$ sudo gnome-mount -t -u -d /dev/hdb1
gnome-mount 0.4
Unmounted /dev/hdb1.
$ sudo gnome-mount -t -u -d /dev/hdb3
gnome-mount 0.4
Unmounted /dev/hdb3.
-
毎朝の自動バックアップ用 Perl スクリプトを書きなおして,
server 上で運転試験.
これは同時に最初の backup でもある.
これはとくに問題もなくうまく動作しているように見える.
-
露崎さんが ThinkPad 240Z を授業で使う,
とのことで
……
同機は年内は露崎さん部屋に滞在予定.
-
ECOAS プランクトンデータにもどる.
-
全 N = seston N + DTN (dissolved inorganic nitrogen)
-
DTN: アンモニア, 硝酸, 亜硝酸態の窒素;
-
DON (dissolved organic nitrogen)
を測定してないので DTN を使う
-
全 P = seston P + DTP (dissolved total phosphorus)
とゆーことなんで,
植物プランクトン (seston) なものとそうでないものにわけてみる.
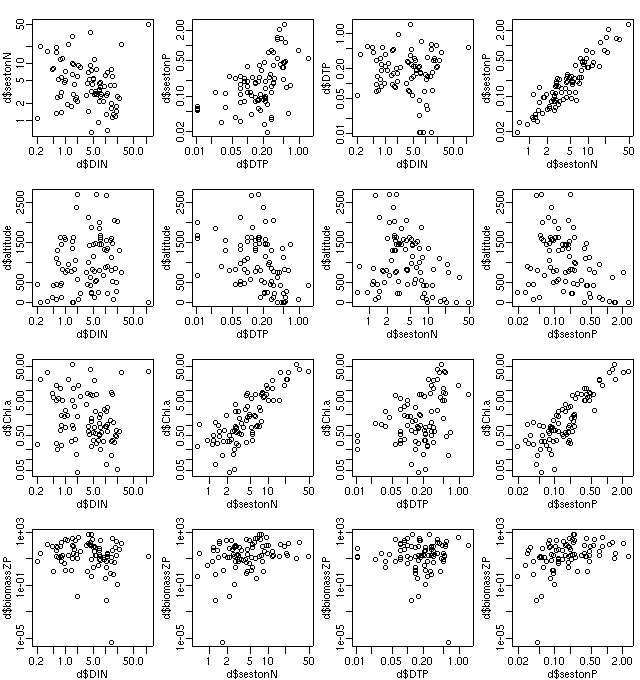
-
うーむ,
やはり seston N や P と Chl-a の濃度は相関高い
(というのもどちらも植物プランクトン内部のモノなので),
ということで,
やっぱり N だの P だのがプランクトン外にあるかどうかを
峻別したほうがいいような.
しかし系全体の栄養塩類量を考えると植物プランクトン内にある量が
無視できんというか
……
生物 ⇔ 無生物間の相互作用というか共分散も
考えないといけいないのかしらん?
うー
-
よくわからないので,
また占部さんに質問メイル.
-
1730 研究室発.
1800 帰宅.
晩飯.
-
明日から 3 日間は書類上の夏休み.
-
[今日の運動]
-
[今日の食卓]
- 朝 (0900):
米麦 0.6 合.
豆腐.
キャベツ・ニンジン・タマネギ・キュウリのサラダ.
- 昼 (1310):
研究室お茶部屋.
米麦 0.6 合.
キャベツ・ニンジン・タマネギ・キュウリのサラダ.
- 晩 (1930):
米麦 0.8 合.
キャベツ・ニンジン・タマネギ・キュウリのサラダ.
ズッキーニのスープ.
2007 年 09 月 03 日 (月)
-
0800 起床.
朝飯.
コーヒー.
怠業
……
う,
今日から書類上の夏休みなんだけど,
ホントに休んでしまった.
-
1220 自宅発.
曇.
1235 研究室着.
-
数セミ原稿の修正.
あれこれ修正,
ファイルアップロード,
数セミ編集部に連絡,
で 1450 ひとまず終了.
-
昼飯.
なぜか (プランクトンとはまた別の ECOAS データである)
雄阿寒岳樹木成長データの雑談,
とか.
-
ECOAS プランクトンデータの統計モデリングの検討.
また占部さんからいろいろと教えていただいたのだが
……
窒素だのリンだのがどこにあるか,
という観測値は
-
何やらいろいろと相互作用のある動態モデルで
記述できる (がそのモデルの定式化されてない?)
-
平衡状態にちかい値
……
と考えられているみたいだねえ.
-
ならば観測したヒトたちのアタマの中にあわせた
統計モデリング,
ということになると
……
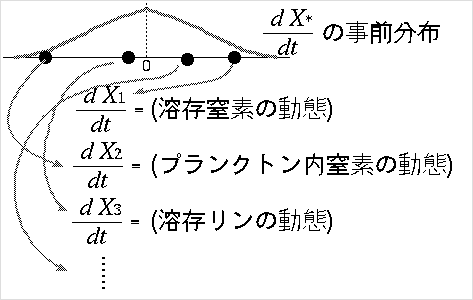
たとえばこういうものになるのではないかな?
-
上の図が示してるモデル,
ちょっとばかり新奇に見えるしろものだなぁ
……
こういう陸水系の生物-無生物の C-H-P のボックスモデルって
ありがちだとは思うんだけど,
ここで系が平衡状態 (dX*/dt = 0) とは考えずに,
「変化量がどれもほぼゼロ」 (dX*/dt がゼロにちかい)
と考えて,
その変化量の分布が Gibbs 分布にしたがうと考えています,
という
……
まあ,
正しいのかどうか,
使いものになるのかどうか,
よくわからぬ統計モデリングではあるな.
-
他にアイデアもないので,
またメイル書いてみる.
・リン添加実験によって Chl-a が増加する
ということで (ECOAS data との対応: Chl-a と DTP, DIN を比較した場合,
DTP のほうが相関が高そうに見える),やはり DTP と seston P は「全リン」
とはまとめずに,わけて考えたほうがよさそうな気がしてきました.
この場合,リン濃度は環境収容力というより,Chl-a 増加速度などを決めてい
るような気がします.平衡状態の現存量は系へのリンの出入りと seston に取
り込まれる速度と放出される速度のかねあいで決まりそうですね.
ということで,推定できるかどうかわかりませんが,何か動態モデルの平衡状
態を満たすようなパラメーターの値をデータから推定せよ,という問題のよう
な気がしてきました.
動物プランクトン・魚その他の影響はあとから考慮することにして,とりあえ
ず植物プランクトンとリンだけあるような系を考えます.DTP である PI と
seston P である PO の濃度は,たとえばと下のようなダイナミスが成立してい
るとします (このダイナミクスは正の平衡状態をもちます):
dPI/dt = r1 - r2 * PI - r3 * PI * PO + r4 * PO
dPO/dt = - r2 * PO + r3 * PO * PI - r4 * PO
r1 は系外からの PI の流入速度,
r2 は系から水が流出する速度で PI も PO もいっしょに流される,
r3 は DTP が seston P になる速度,
r4 は seston P が DTP になる速度,
といったかんじで,たとえば r1, ... , r4 のパラメーターが標高に依存した
り,植物プランクトンの増殖速度である r3 が標高だけでなく PI の増加関数
であればよいように思います (ちょっと現象論的ですが).つまり r のたぐい
が環境要因の関数,たとえば r1 = exp(a + b * height) といった関数になっ
ている,とういことです.
このような式がずらずらと (実際には窒素や動物プランクトンなんかのダイナ
ミクスも列挙されるのでしょうが) あるとして,ここで系が平衡状態に近いと
仮定するわけです.
モデル屋なら dPI/dt = 0 とかおくのでしょうが,われわれは実際の観測デー
タを扱っているので,dPI/dt その他の変化率がゼロに近い,つまりゼロを中心
とする確率分布,たとえば平均ゼロで標準偏差σの正規分布にしたがうと仮定
します.
このダイナミクス全体を階層ベイズモデルとしてあつかうわけですが,
このときに「平衡状態からのずれのばらつき」σがどの式でも共通していて,
しかも尤度を高くするためにはこの値ができるだけ小さくなる方向に,r1,
..., r4 の値を決定するパラメーター (上の例だと a だの b だの) の事後分
布を計算すればよいでしょう.これは GLMM なんかの「個体差は平均ゼロで標
準偏差σの確率分布にしたがうようにする,ただし個体差のばらつきσは可能
なかぎり小さくする」といった考えかたと同じです.
結局のところ,r1, ..., r4 といったパラメーターが標高その他にどう依存す
るか,といった結果が得られるはずだと思います (MCMC 計算がうまく収束し
てくれれば).
1850 研究室発.
1900 帰宅.
体重 68.6 kg.
うんどう.
晩飯.
[今日の運動]
[今日の食卓]
- 朝 (1100):
米麦 0.6 合.
マイタケ・卵の炒めもの.
ネギ・豆腐の味噌汁.
- 昼 (1430):
研究室お茶部屋.
米麦 0.6 合.
インスタント味噌汁.
- 晩 (2200):
米麦 0.8 合.
サンマの塩焼.
モヤシ・ネギ・豆腐の煮物.
キュウリ.
トウモロコシ.
2007 年 09 月 04 日 (火)
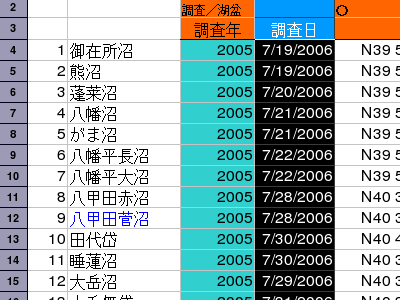
[日付列]
2006 年ってのは観測ではなく入力年ですなぁ.
おうぷんおひすだとこう表示されるんだけど,
gnumeric だと別の日付になってしまう.
いやはや.
CSV 出力すると 2006-07-17 が 37453 という
整数に.
いやはや.
-
昼飯.
-
いろいろとメイルやりとり.
-
上記の観測日変換,
> as.Date("2006-07-17") + d$date - 37453
[1] "2006-07-19" "2006-07-19" "2006-07-20" "2006-07-21" "2006-07-21"
[6] "2006-07-22" "2006-07-22" "2006-07-28" "2006-07-28" "2006-07-30"
[11] "2006-07-30" "2006-07-29" "2006-07-31" "2006-07-31" "2006-07-29"
[16] "2006-08-18" "2006-08-19" "2006-08-19" "2006-08-20" "2006-08-20"
...
てなかんぢで,
day of year 変換は
> as.numeric(format(as.Date("2006-07-17") + d$date - 37453, "%j"))
[1] 200 200 201 202 202 203 203 209 209 211 211 210 212 212 210 230 231 231 232
[20] 232 236 236 237 237 230 232 232 234 234 236 236 237 237 238 239 239 240 241
[39] 241 247 199 200 200 201 206 207 207 216 228 228 229 229 230 235 235 236 237
[58] 237 238 245 245 249 253 253 198 198 199 201 201 202 203 208 209 211 211 212
[77] 229 229 229 230 230 232 232 234 234 234
しかしまあ,
上のような水温モデルの説明変数に使うなら,
単なるこんな量でも問題ないわけで.
> d$date - 37453
[1] 2 2 3 4 4 5 5 11 11 13 13 12 14 14 12 32 33 33 34 34 38 38 39 39 32
[26] 34 34 36 36 38 38 39 39 40 41 41 42 43 43 49 1 2 2 3 8 9 9 18 30 30
[51] 31 31 32 37 37 38 39 39 40 47 47 51 55 55 0 0 1 3 3 4 5 10 11 13 13
[76] 14 31 31 31 32 32 34 34 36 36 36
-
生態遺伝の石崎さんと植物の「匂い物質」
組成
(ガスクロマトグラフィーによる定量,
20 種以上あるうちの 17 種)
の空間統計モデリング
……
とする予定だったのだけど,
お話を拝聴しているうちに,
これって空間相関のハナシとかではなく,
むしろ遺伝相関 (アロザイム 3 遺伝子座,
対立遺伝子数
c(2, 4, 5))
との関連みたほうがいいんじゃないの,
ということで.
-
とはいえ,
手ぶらでおひきとりいただくのも気の毒なので,
R 布教もかねて 17 種の「匂い物質」地図の作図プログラミングを例示,
PDF 出力.
1730 ごろ終了.
-
また ECOAS プランクトンデータの整理.
うーむ,
この集水域の面積とか使うべきなんだろうか.
そして水温なるデータもいまいちよくわからん
……
しかし,
この ECOAS なるぷろぢぇくとが環境省のヒモつきであることを考慮するならば,
やはり水温なるアヤしげな環境要因はモデル化せんといかんだろうよ.
うう.
なんで私なんかが温度とか考慮したプランクトン群集のモデル化
やってるんでしょうねえ
……
-
1940 研究室発.
2000 帰宅.
体重 68.6 kg.
晩飯.
-
[今日の運動]
-
[今日の食卓]
- 朝 (0900):
米麦 0.5 合.
モヤシ・ネギ・豆腐の煮物.
- 昼 (1320):
研究室お茶部屋.
ヒジキ飯.
ミディトマト.
- 晩 (2110):
米麦 0.7 合.
ニラ・ニンジン・ショウガ・エノキダケ・豚肉のカレー.
キャベツ・ネギのサラダ.
キュウリ.
2007 年 09 月 05 日 (水)
-
0730 起床.
書類上の夏休み 3 日目,
最終日.
朝飯.
コーヒー.
0915 自宅発.
曇.
0930 研究室着.
-
伊庭さんから数セミ原稿についていろいろとコメントいただいたので,
それにそった修正.
おそるおそる編集部に連絡してみる.
まあ,
ダメだったら校正の段階であれこれ修正する,
と.
-
どうも私の場合,
「原稿みなおし」
という作業に関して
みなおし回数が増えるにつれて,
劇的に粗雑化していくように思う.
どうにかならんものかね
……
-
また ECOAS プランクトンデータの統計モデリングの検討.
植物プランクトン体内での窒素 : リン = だいたい一定,
を実現する方法がわからん
……
たとえば,
乱暴かもしれないけど,
おおよそ
No : Po = f : 1
ふきんをふらふらさせるにはにするためには
dNo/dt = ... + r * Ni * No * (f * Po - No) + ...
dPo/dt = ... + r * Pi * Po * (No - f * Po) + ...
とすればよいのかしらん?
-
それとも,
そもそもこんなよけーなものつけなくてもいいのだろうか?
……
いやいや,
系全体が「平衡」状態でない場合であっても,
植物プランクトン体内の窒素 : リンはめちゃくちゃにならないだろうから,
何か上のような安定化のしくみが必要だよなあ.
-
とはいえ,
すといきおめとりーだか何だか生物の体の中における
「物質 A : 物質 B = 一定」
なる考えかたってホントに正しいのか?
あろめとりっくだとすると,
log(A) : log(B) = ほぼ一定,
ぐらいかもしれないじゃないか?
ECOAS データの「観測値」の散布図でみるとそんなかんぢだ.
だとすると,
上の式は
dNo/dt = ... + r * Ni * No * (f * log(Po) - log(No)) + ...
dPo/dt = ... + r * Pi * Po * (log(No) - f * log(Po)) + ...
てなことになってしまうのかしらん?
まあ,
でもプランクトンというコンパートメントを考えると,
やはり log ぬきのほうが妥当なのかなぁ.
しかし上のように窒素・リンの取りこみ速度を
こういうふうに制約してしまうとぜんぜん動かなくなるような気がする.
系が不安定ならいいんだけどね.
やっぱり炭素動態も明示的に書かんといかんのかしらん?
Chl-a の動態で代替できる?
dNo/dt = ... + r * Ni * Ca * g1(Ca - fN * No) + ...
dPo/dt = ... + r * Pi * Ca * g1(Ca - fP * Po) + ...
dCa/dt = ... + g2(No, Po) * Ca + ...
この g1 だの g2 だの
がややこしい関数になりそうだけど,
まあどうしようもないよね.
いやはや.
などと考えつつ昼飯.
とりあえず,
水温データの階層ベイズモデル化.
> summary(as.matrix(post.mcmc)[, c("wt.a", "wt.d")])
wt.a wt.d
Min. :-0.00477 Min. :-0.0127
1st Qu.:-0.00311 1st Qu.: 0.0443
Median :-0.00270 Median : 0.0591
Mean :-0.00270 Mean : 0.0586
3rd Qu.:-0.00222 3rd Qu.: 0.0744
Max. :-0.00119 Max. : 0.1147
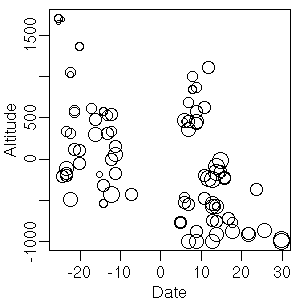
[ただし,だ ……]
観測日があとになるほど標高の低いところに移動している,
という交絡はあるんだよね.
まあ,
しょうがない.
-
あ,
「年」変動いれるの忘れてた,
と思って念のため調べてみると
……
> tapply(d$altitude, d$year, summary)
$`2003`
Min. 1st Qu. Median Mean 3rd Qu. Max.
5 115 250 357 660 845
$`2004`
Min. 1st Qu. Median Mean 3rd Qu. Max.
5 232 660 687 852 2120
$`2005`
Min. 1st Qu. Median Mean 3rd Qu. Max.
419 658 1130 1130 1530 2000
$`2006`
Min. 1st Qu. Median Mean 3rd Qu. Max.
815 1450 1560 1670 1930 2700
……
観測年によって調べている標高がぜんぜんちがう
……
これが!
野外観測データだッ!
(東北地方が中心になっているということで,
BAOH
ナレイションふうに叫んでください)
-
よくわからんまま,
いちおう年変動もいれてみるか.
あ,
緯度いれるのも忘れてた
……
ということでそのあたりモデルを変更してみた結果.
> summary(post.mat[, grep("^wt.[maldy]", colnames(post.mat))])
wt.m wt.a wt.l wt.d
Min. :16.6 Min. :-0.004162 Min. :-0.704 Min. :-0.00679
1st Qu.:17.3 1st Qu.:-0.002885 1st Qu.:-0.309 1st Qu.: 0.05031
Median :17.6 Median :-0.002494 Median :-0.197 Median : 0.07077
Mean :17.6 Mean :-0.002480 Mean :-0.197 Mean : 0.07051
3rd Qu.:17.8 3rd Qu.:-0.002044 3rd Qu.:-0.085 3rd Qu.: 0.09212
Max. :18.9 Max. :-0.000617 Max. : 0.368 Max. : 0.16420
wt.y[1] wt.y[2] wt.y[3] wt.y[4]
Min. :-2.4010 Min. :-1.1920 Min. :-2.0170 Min. :-2.4560
1st Qu.:-0.2997 1st Qu.:-0.0318 1st Qu.:-0.0760 1st Qu.:-0.4274
Median :-0.0279 Median : 0.0800 Median : 0.0557 Median :-0.0720
Mean :-0.1460 Mean : 0.3046 Mean : 0.1192 Mean :-0.2371
3rd Qu.: 0.0890 3rd Qu.: 0.5906 3rd Qu.: 0.3653 3rd Qu.: 0.0377
Max. : 1.7660 Max. : 2.8530 Max. : 2.1380 Max. : 1.5140
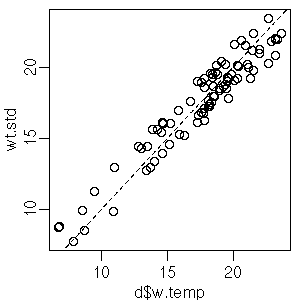
[タテ軸は日・年補正した平均水温]
まあ,
補正してもほとんどかわらん.
変数名は
wt.std
より
wt.adj
とかにしたほうがいいかな?
……
というか,
「補正」とかやらなくてもいいような気もしてきた.
こういう山地の湖沼の生態系の回転速度がわからんのだけど,
もし気温の日変化速度よりも窒素・リンの変動が速ければそれでいいわけで.
うーむ,
へいこう状態って何なのでしょう.
実際には平衡でも何でもないんだろうなあ.
こういうやってもやらなくてもよさそうな水温のモデリングに
手をつけたのは,
他にも理由があって
……
ゐんばぐす呼び出し
のしくみを関数化によって多少はすっきりできないだろうか,
というアイデアがあって,
それをちょっと実装してみて試験してみたかった次第だ.
下のごとく,
library(R2WinBUGS)
の wrapper 関数群を定義したら,
多少はマシではなかろうか,
と.
source("WinBUGS.R")
load("../data/d.RData")
set.data(list(
N.site = nrow(d),
N.year = 4,
#
W.temp = d$w.temp,
Altitude = d$altitude - mean(d$altitude),
Latitude = d$latitude - mean(d$latitude),
Date = d$date - mean(d$date),
Year = d$year - 2002, # 1:4
#
Tau.error.wt = 10,
Tau.noninformative = 1.0e-3,
Hyper.gamma = 1.0e-3
))
clear.param()
set.param("wt.m", 0)
set.param("wt.a", 0)
set.param("wt.l", 0)
set.param("wt.d", 0)
set.param("wt.y", rep(0, N.year))
set.param("d.wt", rnorm(N.site, 0, 0.01))
set.param("tau.wt.y", 1)
set.param("tau.d.wt", 1)
set.param("wt.adj", NA)
post.bugs <- call.bugs(n.iter = 5000, n.burnin = 1000, n.thin = 20)
これだってめんどくさいぢゃん,
と思われるかもしれないけど,
今までに比べれば
「圧倒的にすっきり」
(当社比)
書けてるのである.
しかも,
この見かけより重要なのはモデリング試行錯誤がやりやすく
(当社比)
なってる,
というあたりだ.
1815 研究室発.
1830 帰宅.
体重 68.0 kg.
プランクトンやせ,
か.
うんどう.
晩飯の準備.
晩飯.
ベイズモデルでどうやればすっきりモデル選択みたいなことができるのか,
いまいちよくわからない.
そういう研究はいろいろとある.
たとえば,
mixture prior
を使う,
といった方策だ
……
これって実装が少しばかりめんどくさそうだ.
[今日の運動]
[今日の食卓]
- 朝 (0800):
米麦 0.5 合.
ニラ・ニンジン・ショウガ・エノキダケ・豚肉のカレー.
- 昼 (1340):
研究室お茶部屋.
ヨーグルト.
リンゴ.
- 晩 (2100):
米麦 0.8 合.
ネギ・ピーマン・豆腐・卵の炒めもの.
キャベツ・ネギのサラダ.
コマツナのゴマあえ.
キュウリ.
2007 年 09 月 06 日 (木)
-
0720 起床.
朝飯.
コーヒー.
0850 自宅発.
曇.
0905 研究室着.
-
ECOAS プランクトンデータ解析,
動態モデルをまとめてみる.
-
昼飯.
-
動態モデルを構成するパラメーターの整理,
いろいろと試行錯誤.
-
とびこみデータ解析こんさる.
東研の藤原君でアリ血縁度のハナシ.
Queller & Goodnight (1989)
の頻度をやたらと足し引きして割算値化する
Relatedness 5.0 なるすごく古いソフトウェア依存な方向のもので
……
こういう古い集団遺伝学由来の,
とでも形容すべき指標あれこれは見てていつも気分が悪くなるんだけど,
Bayes とかもちこんできちん統計モデル化するのはしんどいので,
いつもそのまま放置してしまう.
今回も Relatedness の挙動を二人して検討し,
まあ皆さんこの指標が正しいと思ってるんなら
あとは jackknife な信頼区間で種間比較でも,
といったいいかげんな策にオワる.
-
ゐんばぐす
coding.
こりゃ,
なかなかたいへんだわ.
-
そしてばぐ取り,
というか,
ゐんばぐすの不親切な trap 窓エラーがでたら何か
統計モデリングの不備があるはずと確信してそれを見つけだす作業.
ゐんばぐすはそれほど難しいソフトウェアではないけれど,
この過程だけは
かなりの
洞察力を要求される.
おそらくゐんばぐすというか階層ベイズモデル普及を遅らせる原因となるだろう.
-
たとえば下の例でいうと,
隠れ変数
biomass
を導入するに際して,
Tau1
と
Tau2
の関係をどうすればよいか,
といった問題だ.
これは,
どちらも無情報事前分布にしては
いけない
場合なのである.
私も意味不明エラー窓をつきつけられるまでは気づかなかった.
biomass[i] ~ dnorm(0, Tau1)
logit(p.fish[i]) <- phi[1] + phi[2] * biomass[i]
Fish[i] ~ dbern(p.fish[i])
for (k in 1:2) {
phi[k] ~ dnorm(0, Tau2)
}
そしてこのような小手先の問題ではなく,
「平衡状態付近を Gibbs サンプリング」
なる今回の奇策がじつはかなりヘンだということが徐々にわかってきた
……
ゐんばぐすは全パラメーターを「なかったこと」にすることで,
「平衡状態」
の実現をもくろんでいる.
いやはや,
これは事前に気づくべきだったんだけど,
やはりそういう計算結果がでるまで気づかなかったよ
……
へろへろになってきたので
2140 研究室発.
2155 帰宅.
体重 68.4 kg.
晩飯.
計算試行錯誤つづける.
ちょっとやそっとの小細工ではどうにもならん
……
夜中の散歩.
歩いているうちにようやく解決策をひとつ思いついた.
これは「平衡状態」とやらをあつかっているので,
どれかひとつの rate を
「一般性を失うことなく」
(without losing generality, without loss of generality)
何か定数,
たとえば 1 に固定してよいわけだ!
今晩はもう計算はやらないけど,
明日はこの方向で試行錯誤してみよう.
[今日の運動]
[今日の食卓]
- 朝 (0750):
米麦 0.7 合.
キムチ・豆腐・卵の炒めもの.
- 昼 (1220):
道外からのお客様たちと楽しくスープカレー.
またまた北 16 西 4
「心」
で.
今日はラビオリカレー,
辛さ 8 (これは前回の 7 とほとんど変わらない),
小ライスで.
- 晩 (2220):
スパゲッティー.
レトルトパウチドのアサリソース.
キュウリ.
2007 年 09 月 07 日 (金)
-
0750 起床.
朝飯.
コーヒー.
0910 自宅発.
曇ちょっと雨.
台風 9 号が接近中.
0925 研究室着.
-
ECOAS プランクトンデータ解析の統計モデルてなおし.
系から流出する速度を 1 に固定すればうまくいくはず
……
うーむ,
マシにはなったけどまだまだダメ.
-
モデルを単純化する作業
……
つまり一種の撤退戦闘を連想させる苦行が始まる.
とりあえず魚バイオマスの動態を抜きとる.
次に動物プランクトンも
……
うーむ,
動態データがないときに動態パラメーターを推定しようとする
試みがこれほどしんどいものであった,
とは.
-
昼飯.
ぢつは本日あった午前午後の会議は「忘れて」いるのである.
午前のは天然ぼけで.
午後は「環境科学院全体だからすごいスシづめになるよ」
と甲山さんに教えていただいので,
非天然で.
-
……
で,
夕方まで悪戦苦闘が続いたんだが
……
この観測データセットからは高山湖沼の栄養塩類・プランクトン動態モデル
のパラメーター推定は不可能,
と確信がもてるようになったので,
撤退.
やれやれ.
がっくり.
-
がっくりしてたらまた査読依頼が.
がっくり度が強まってしまったので,
しばらく無視無視.
-
ということで,
もっと静的で現象論的な統計モデルを作りなおすことに.
まあ,
ここまでの一連のモデリング試行錯誤で水中生態系の抽象化の方策は
少しは理解できるようになったから,
そのあたりを利用して,
と.
-
その前に,
ちょっとめんどうな Chl-a - Seston N - Seston P
の関係を再確認
……
つまりこれって対数三次元空間内の
「ほぼ直線」
みたいなもんだよな.
ということは,
これって説明変数 vs 応答変数という関係ではなくて
……
「植物プランクトンの活性をあらわす変数」
(あとで結局これは Chl-a そのものになった)
がいろいろなカタチで「発現」している,
というモデリングになるわけだ.
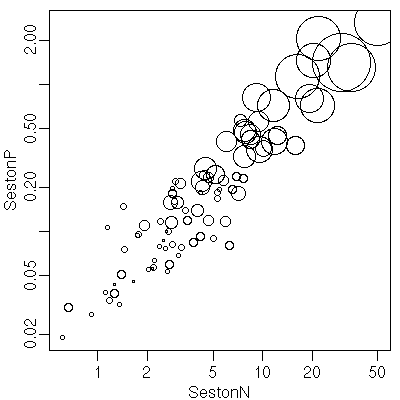
-
ということで,
また BUGS 言語による階層ベイズモデルのプログラミング.
-
例によってナゾの Trap 窓エラーと戦う.
これは感覚的には,
泳げないのにいきなり水の中にほうりこまれてもがいてるうちに,
どうにかこうにか泳げるようになる,
というかんぢだ.
-
そのようにエラーなおしつつ,
いろいろなことに気づく.
魚のいる・いないをよりよく説明していたのは
標高ではなくて log(池面積) だった
……
-
しかし収束が悪い
……
おそらくゐんばぐす内で Gibbs sampler ではなく
Metropolis-Hastings 法にきりかわっているためだろう
……
しかし統計モデリングの改善でこのあたり,
なんとかならんかな,
と.
-
収束に関してはあまり改善されず,
チカラつきてきたので撤退.
2150 研究室発.
2205 帰宅.
-
[今日の運動]
-
うんどう休養日
……
まあ,
いろいろ走ったりしたのだけど
-
[今日の食卓]
- 朝 (0820):
米麦 0.7 合.
豆腐の味噌汁.
コマツナのゴマあえ.
キムチ.
- 昼 (1350):
研究室お茶部屋.
米麦 0.8 合.
レトルトパウチドカレー.
- 晩 (2030):
研究室.
こんびにいなり寿司.
2007 年 09 月 08 日 (土)
-
0800 起床.
朝飯.
コーヒー.
洗濯.
そうじ.
怠業.
1120 自宅発.
台風 9 号通過したあとの晴.
今日は気温たかくなるもよう.
1145 研究室着.
-
そういえば昨日,
荒木飛呂彦先生のイラストが Cell の表紙に!
というけっこうショッキングなニュースが駆けめぐりましたなぁ
……
牧先生とか発奮しておられるにちがいない.
私もせいぜい良い論文を書いて,
吉田戦車画伯に表紙を描いてもらおう.
-
また ECOAS プランクトンデータの階層ベイズモデル化にとりくむ.
一晩ねてアタマがすっきりしたおかげなのか,
BUGS コーディングの改善点がわかったような気がした
……
で,
試してみるとうまくいった.
最終的な結果を得るためにはやはり
10000 MCMC step 超の計算が必要だろうけど,
混交は格段によくなっている.
-
改善点 (らしきもの)
の要点はこうだ.
統計モデリングをするときに fixed effects
と random effects のパラメーターをわけて考えるクセがついていると,
こういうコーディングになりがちなんだけど
# coding 1
for (i in 1:N.x) {
...
x[i] <- beta0 + beta1 * z[i] + re[i]
re[i] ~ dnorm(0, tau.re)
...
}
もしデータ構造が下のような書きかたを許すのであれば
(つまりひとつの対象 i から 1 回だけデータを得た場合だ),
# coding 2
for (i in 1:N.x) {
...
x[i] ~ dnorm(mu.x[i], tau.re)
mu.x[i] <- beta0 + beta1 * z[i]
...
}
このように書いたほうが混交が改善されるように思う.
少なくとも,
計算速度はかなり改善される.
ただしモデルとデータ構造によっては
こういうカタチに書きなおすことができないので,
注意.
-
……
しかし Trap 窓は忘れたころにやってくる
……
と思ったらこれは単純なコトで,
負の値の log を計算させてた.
-
計算させつつ昼飯.
-
階層ベイズモデル,
ぢりぢりと改善されつつある.
パラメーター数が多いので定常状態に到達するまで
かなり時間かかるのはしょうがない,
のかしらん?
……
ぢつは,
ゐんばぐすを用いた計算でこの時間を短縮するために有効なワザは
「説明変数の
中央化
(説明変数の平均がゼロに近いこと)」
なのである.
うん,
なんだかいつも理不尽に思えてしまうんだけど,
そうなっているのだ.
そして統計モデル中で生成される説明変数 (隠れ変数)
をうまくあつかわねばならぬ,
というあたり,
よくよく注意する必要あるわけで.
-
しかしこのあたり,
小細工にハシりすぎると計算がどんどんおかしくなるわけで.
-
21000 MCMC step で 390 秒ぐらい,
混交はもうちょい
……
魚いる・いないモデルから「水温」なる説明変数をぬくか.
-
……
といったコトどもが問題なのではなく,
ここによーやくにして
「モデルが複雑になると MCMC 計算がふらふらしなくなるのか?」
がわかってきたよーな気がする.
うーむ
……
おそらく,
なのだけど,
説明変数は可能なかぎり確率変数化せよ,
といった原則があるように思えてきた.
-
WinBUGS の中では変数は確率変数かそうでないか,
のふたとおりある.
推定すべきパラメーター数が少ないときは,
とくに何も考えずにモデリングしても,
Gibbs sampler はしゃかしゃか走りまわってくれる.
-
ところが,
パラメーター数が増えて,
変数のあちこちに (交互作用ではなく)
相互作用があるような場合には
……
これらの変数は
(上述のように random effects と関連づける,
など何かうまい口実をもうけて)
確率変数化する必要がある
(BUGS 言語で言えば
~ で生成される変数).
-
というのも,
決定論的な変数 (
<- で生成される変数)
が説明変数としていくつも含まれているようなモデルは「カタい」と申しますか,
あちこちにシバりがあって Gibbs sampler が自由には動きまわれぬ,
と見えるんだよね.
-
ともかく,
今回のモデリングに関してはこういうふうに変更してみると,
「どうしてココは動かんのだろねぇ」
というところがクビキをとかれたようにしゃかしゃかしはじめた.
いやー,
今まで気づかんかった
……
-
そして魚いる・いないモデリングを logistic
な定式化から,
ポアソン分布にもとづくもの
(コーディングでは
dcat(p.fish[i,])
をもちいる)
に変更してみる.
いる・いない問題だからといっても何でもかんでも
logistic にすればいいってモンじゃないしね.
得られた結果もわかりやすくなってるように思う.
-
いろいろ試行錯誤して,
まっとうそうな計算結果得られた.
ssh 経由で使ってる A801 の Dell desktop 機で 160 秒.

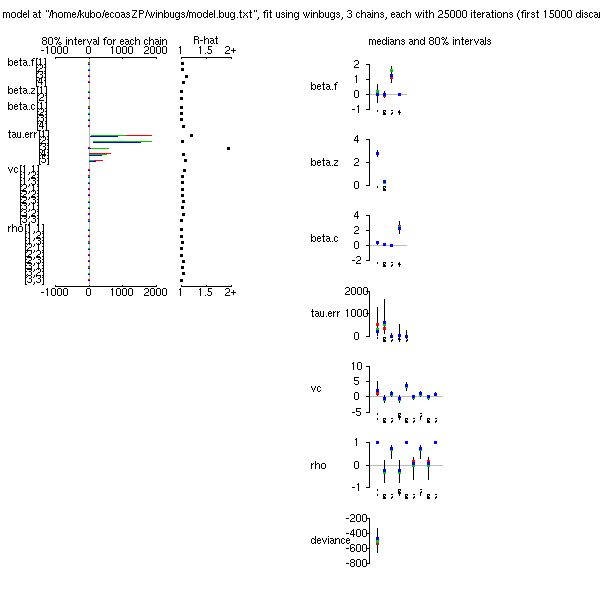
Inference for Bugs model at "/home/kubo/ecoasZP/winbugs/model.bug.txt", fit using winbugs,
3 chains, each with 16000 iterations (first 10000 discarded), n.thin = 30
n.sims = 600 iterations saved
mean sd 2.5% 25% 50% 75% 97.5% Rhat n.eff
beta.f[1] -0.71 0.45 -1.53 -1.04 -0.73 -0.41 0.18 1.00 600
beta.f[2] 0.89 0.25 0.40 0.73 0.89 1.04 1.41 1.02 130
beta.f[3] -0.16 0.15 -0.46 -0.24 -0.16 -0.06 0.11 1.01 450
beta.f[4] 1.34 0.13 1.10 1.26 1.34 1.43 1.57 1.01 600
beta.z[1] -0.12 0.00 -0.12 -0.12 -0.12 -0.12 -0.12 1.00 1
beta.z[2] 2.43 0.00 2.43 2.43 2.43 2.43 2.43 1.07 64
beta.z[3] 0.50 0.36 -0.25 0.28 0.51 0.73 1.15 1.03 130
beta.z[4] 0.20 0.12 -0.02 0.12 0.21 0.28 0.43 1.03 94
beta.c[1] -0.10 0.21 -0.59 -0.21 -0.08 0.04 0.21 1.02 170
beta.c[2] 0.64 0.54 -0.24 0.24 0.57 0.93 1.81 1.01 280
beta.c[3] 0.25 0.07 0.14 0.20 0.25 0.30 0.41 1.01 390
beta.c[4] 0.00 0.01 -0.02 0.00 0.00 0.01 0.02 1.04 66
beta.c[5] 2.72 0.72 1.33 2.29 2.75 3.14 4.18 1.01 190
tau.err[1] 30.19 33.70 1.13 6.32 17.88 41.49 127.30 1.00 600
tau.err[2] 941.65 829.95 93.97 341.90 683.70 1308.25 3069.92 1.00 600
tau.err[3] 54.72 175.42 0.05 0.24 2.75 19.75 665.88 1.02 110
tau.err[4] 54.34 223.75 0.00 0.00 0.11 8.58 537.04 1.21 14
tau.err[5] 150.44 334.49 3.28 14.22 41.55 129.35 910.75 1.00 600
tau.delta[1] 0.14 0.03 0.08 0.11 0.13 0.16 0.20 1.00 600
tau.delta[2] 0.33 0.15 0.17 0.24 0.29 0.37 0.64 1.02 420
tau.delta[3] 5.59 24.88 0.61 0.94 1.49 3.36 25.40 1.03 120
tau.delta[4] 108.36 258.86 0.51 1.19 5.65 75.45 907.25 1.03 110
deviance -250.71 140.08 -495.42 -350.30 -263.80 -159.12 9.43 1.01 320
For each parameter, n.eff is a crude measure of effective sample size,
and Rhat is the potential scale reduction factor (at convergence, Rhat=1).
pD = 282.3 and DIC = 31.6 (using the rule, pD = Dbar-Dhat)
DIC is an estimate of expected predictive error (lower deviance is better).
-
へろへろと撤退.
1850 研究室発.
はてさて,
上のモデルは因果関係で
魚-動物プランクトン-植物プランクトンの
観測値間の関係を説明しようとしたわけだけど
(BUGS code)
……
いろいろと他にも改善すべきところはあるんだけど,
じつはこのあたりこそが
(例の呪われ Wishart 分布から生成されてしまった)
分散共分散行列に駆動される多変量正規分布な事前分布
(その平均値は種間相互作用ナシ条件化のもの)
を使って生成するべきなのかも,
という気がしてきた.
つまりこのデータからは因果関係は推定不可能であり
(原理的に),
相関関係だけが推定可能なのかも,
というハナシで
……
北 12 生協で買いもの.
1910 帰宅.
晩飯の準備.
晩飯.
-
[今日の運動]
-
[今日の食卓]
- 朝 (0900):
クルミパン.
オレンジ.
ナシ.
- 昼 (1310):
研究室.
北 12 生協の納豆巻.
ミディトマト.
- 晩 (2030):
米麦 0.8 合.
ネギ・豆腐の味噌汁.
煮魚.
コマツナのゴマあえ.
キャベツ・ニンジン・キュウリ・ネギのサラダ.
2007 年 09 月 09 日 (日)
-
0800 起床.
朝飯.
コーヒー.
1000 自宅発.
曇,
ちょっと雨.
1015 研究室着.
-
ECOAS プランクトンデータの統計モデリング,
昨日の進捗でどーにかこーにかなったんだけど,
もう一歩だけススめてよく考えてみる必要がある.
-
基本的にこれは難問だ.
しくみがよくわかっていないシステム,
データはスナップショット的なものだけ,
という状況でしくみを無理矢理に推定しようと試みているからだ.
-
群集生態学というと,
観測データから
いつもいつも「相互作用」が推定できてとうぜんのもの,
とわれわれは考えがちなんだけど
……
あたりまえのことながら,
どんなデータからでもそれが推定できるとは考えにくい.
ECOAS プランクトンデータの分量はかなりのものなんだけど,
だからといってここに「しくみ」を推定できるような情報が
そもそも含まれているのだろうか,
と検討してみると
……
じつは「そんなものはない」
という気がしてるんだよね.
ここ数日.
昨日,
無理矢理に推定してみせたにもかかわらず.
-
魚-動物プランクトン-植物プランクトン-栄養塩類の
「相互作用」
(つまり,
A が B を食って B が C を吸収して,
といったあれこれの速度)
は推定できないものと仮定してみよう.
その状況のもとにおいて,
ECOAS の文脈にそって,
ハナシを再検討してみる.
-
一番単純な
(つまり現実ばなれした)
モデル (model 0) からスタートする:
調査地 (池・沼・湖)
の標高・緯度経度が決まると,
いろいろな水温・調査地の面積・窒素リンの流入・流出など
環境要因が決定される;
さらに,
(いろいろな人間の知らない
相互作用の結果として)
栄養塩類の濃度,
プランクトンのバイオマス,
魚の密度が
決まっていくとする
-
このときにわれわれには
「存在しているはずの」
相互作用はみえない
(ホントは相互作用によっていろいろな分量が決まっている
にもかかわらず);
あたかも観測対象が自分のいる標高・緯度経度を
知ってその分量を決めているかのように見えている;
つまり,
あたかも
環境要因だけで生態系の構造が決まっているかのように見える
-
(もし時間変化のない
ある時間断面だけの観測データしかないとすると)
こういう状況では環境要因だけで
プランクトンの現存量その他あれこれを
「説明」するしかない;
環境要因を説明変数とする統計モデリング
(model 0)
の推定による
-
しかしながら,
手もとの観測データをみると標高・緯度経度だけで
何もかも決まっているようには見えない,
環境要因も生物まわりの観測量も
-
model 0 の予測から
(「model 0 の予測」
なるものをどう構成すればよいのか
知らないにもかかわらず),
調査地 i における対象 j
(j = {1, 2, 3} とする; 動植物プランクトンまたは魚)
の観測量がずれている分量を delta[i,j]
とする
-
このときにある調査地 i における
delta[i,1],
delta[i,2],
delta[i,3]
が好き勝手にずれているなら,
delta[i,j] はそれぞれ独立した一変量の事前分布から
生成されている,
と考えればよい (昨日の階層ベイズモデル);
われわれには依然として生物間の相互作用なるものは見えない
-
もし
delta[i,1],
delta[i,2],
delta[i,3]
のずれが各調査地において独立でないなら
(例: 魚のずれがプラスだと,
動物プランクトンのずれはマイナスである確率が高い,
など),
delta[i,j] は三変量確率分布の事前分布から
生成されている,
と考えればよい;
われわれには
依然として生物間の相互作用なるものは見えないけれど,
推定された (事前分布の) 分散共分散行列から,
生物間の「相関」は見ることができる
ということで,
-
環境要因で説明される
model 0 なる「平均的な変化」
-
生物間の現存量のずれ
delta[i,*]
間の相関をあらわす分散共分散行列
(Wishart 分布を超事前分布とする)
のふたつを同時に推定できるような,
多変量事前分布の階層ベイズモデルを構築すればよろしい,
というハナシなのかな?
-
Wishart 分布は昨年
11/23
あたりにも苦闘してたわけだが
……
-
うーむ,
ゐんばぐす
の
多変量正規分布
dmnorm(mu[], tau[,])
と
Wishart 分布 dwish(R[,], Deg.freedom)
使った階層ベイズモデルの coding はできたんだけど,
やはりこのふたつの関数の挙動がよくわからん.
簡単な数値例をつかってこいつらの正体を解明せんといかんな
……
-
その前に,
昼飯.
-
とびこみメイル
R
こんさる.
これが唯一の回答ではぜんぜんないんだけど,
まあ,
一番てぬきして書くとこうなる,
の一例.
# 個体数 N.invidual の個体をグループ数 N.group のグループ
# にランダムに分配する
N.group <- 5
N.individual <- 10
counter <- summary(
as.factor(sample(N.group, N.individual, replace = TRUE)),
maxsum = N.group
)
result <- counter[as.character(1:N.group)]
names(result) <- 1:N.group
result <- sapply(result, function(x) ifelse(is.na(x), 0, x))
print(result)
まあ,
初心者は
summary(as.factor(...))
わざとか思いつかないのかも.
だとすると,
こうか?
N.group <- 5
N.individual <- 10
result <- rep(0, N.group)
names(result) <- 1:N.group
for (i in 1:N.individual) {
g <- sample(N.group, 1)
result[g] <- result[g] + 1
}
print(result)
とはいえ,
いつまでも for (...) { ... }
なのも進歩がないよねえ,
ということで.
-
さてさて,
ゐんばぐすの
多変量正規分布
dmnorm(mu[], tau[,])
と
Wishart 分布
dwish(R[,], Deg.freedom)
の両関数の挙動をさぐる実験開始.
まずは
dmnorm(mu[], tau[,])
から.
BUGS 言語でこのようにベイズモデルを定義し
model
{
for (i in 1:N) {
Y[i, 1:2] ~ dmnorm(mu[], Tau[,])
}
mu[1:2] ~ dmnorm(Zero[], Tau[,])
}
これを動かす R コードはこうなる.
先日
つくった WinBUGS.R
で定義した関数群のおかげで,
こういう実験が格段にやりやすくなった,
というわけだ
(という効果も期待して作った).
source("WinBUGS.R")
library(MASS) # for mvrnorm()
N <- 1000
set.data(list(
N = N,
Y = mvrnorm(n = N, mu = c(0, 0), Sigma = diag(1, 2)),
Zero = c(0, 0),
Tau = diag(100, 2)
))
clear.param()
set.param("mu", c(1, 2))
post.bugs <- call.bugs(n.iter = 200, n.burnin = 0, n.thin = 1)
print(post.bugs, digits.summary = 3)
とりあえず,
無相関な二変量正規乱数のサンプルの平均を推定させてみる.
問題なのは決めうち分散共分散行列
Tau = diag(100, 2)
の挙動なんだが
……
実行すると
mean sd 2.5% 25% 50% 75% 97.5% Rhat n.eff
mu[1] 0.017 0.003 1.200e-02 1.500e-02 1.700e-02 0.02 2.400e-02 1.006 600
mu[2] 0.018 0.003 1.100e-02 1.600e-02 1.800e-02 0.02 2.400e-02 1.008 240
となった.
推定値の sd が小さいな
……
ということで,
今度は
Tau = diag(0.01, 2)
で計算させてみると
mean sd 2.5% 25% 50% 75% 97.5% Rhat n.eff
mu[1] 0.012 0.318 -0.572 -0.192 0.011 0.240 0.633 1.002 600
mu[2] -0.015 0.323 -0.675 -0.229 -0.021 0.216 0.575 1.007 250
となった.
つまり WinBUGS の
一変量正規分布 dnorm(mu, tau)
で tau
を分散の逆数を指定するのと同じく,
多変量の場合は分散共分散行列の逆行列を指定しないといけない
(逆数の行列でないことに注意).
-
次の実験.
多変量正規分布の分散共分散行列の無情報事前分布として使いたい
Wishart 分布の関数
dwish(R[,], Deg.freedom)
の挙動を調べたい.
実験用コードを下のように変更して,
テストデータを相関のある (相関係数 0.7)
二変量正規乱数としてみる.
source("WinBUGS.R")
library(MASS) # for mvrnorm()
N <- 1000
set.data(list(
N = N,
Y = mvrnorm(n = N, mu = c(0, 0), Sigma = matrix(c(2, 1.4, 1.4, 2), 2, 2)),
Zero = c(0, 0),
Tau = diag(0.01, 2),
R = diag(0.1, 2),
Deg.freedom = 2
))
clear.param()
set.param("mu", c(1, 2))
set.param("tau", diag(1, 2))
set.param("var.cov", NA)
post.bugs <- call.bugs(n.iter = 200, n.burnin = 0, n.thin = 1)
BUGS code のほうはこんなかんぢで.
組み込み関数 inverse(m)
は m の逆行列を生成する.
model
{
for (i in 1:N) {
Y[i, 1:2] ~ dmnorm(mu[], tau[,])
}
mu[1:2] ~ dmnorm(Zero[], Tau[,])
tau[1:2, 1:2] ~ dwish(R[,], Deg.freedom)
var.cov[1:2, 1:2] <- inverse(tau[,])
}
で,
これを計算させると正しく分散共分散行列が推定できてるように見えるよね
……
mean sd 2.5% 25% 50% 75% 97.5% Rhat n.eff
mu[1] 0.050 0.048 -0.048 0.018 0.050 0.083 0.138 0.999 600
mu[2] -0.024 0.044 -0.115 -0.054 -0.023 0.008 0.055 1.001 600
tau[1,1] 0.981 0.043 0.903 0.951 0.977 1.009 1.067 1.010 210
tau[1,2] -0.710 0.038 -0.782 -0.734 -0.710 -0.685 -0.643 1.007 350
tau[2,1] -0.710 0.038 -0.782 -0.734 -0.710 -0.685 -0.643 1.007 350
tau[2,2] 1.014 0.044 0.932 0.984 1.015 1.043 1.098 0.999 600
var.cov[1,1] 2.075 0.091 1.908 2.011 2.070 2.136 2.260 1.001 600
var.cov[1,2] 1.453 0.080 1.287 1.398 1.453 1.507 1.611 1.000 600
var.cov[2,1] 1.453 0.080 1.287 1.398 1.453 1.507 1.611 1.000 600
var.cov[2,2] 2.007 0.091 1.830 1.942 2.008 2.064 2.186 1.000 600
deviance 6397.262 3.490 6393.000 6395.000 6397.000 6399.000 6405.000 1.007 600
つまり関数
dwish(R[,], Deg.freedom)
はウィシャート分布ではなく,
その逆行列を生成する逆 Wishart 分布
(inverse Wishart distribution)
である,
ということが確認できた.
-
残されたナゾは無情報化したい逆ウィシャート分布
tau[1:2, 1:2] ~ dwish(R[,], Deg.freedom)
のパラメーター
R[,] と Deg.freedom
の指定方法なんだが
……
よくわからん.
-
上のような簡単な例題だと
R[,]
をどう指定してもだいたい正しく分散共分散行列を推定する
-
ただしあとでプランクトンデータでやってみると
R[,]
分散 (分散の逆数?)
が大であるときは推定される分散共分散行列の要素の
事後分布が小さくなるような気がする
-
自由度
Deg.freedom
は大きくすると
推定される分散共分散行列の要素の
事後分布が小さくなる
-
ということで,
今回の実験の結果をまとめると,
WinBUGS において
-
多変量正規分布の関数
dmnorm(mu[], Tau[,])
では Tau[,]
に分散共分散行列の逆行列を指定する
-
関数
dwish(R[,], Deg.freedom)
は逆 Wishart 分布の関数であり,
ここから得られた行列を分散共分散行列にするためには
inverse()
を使う
といったところか.
-
で,
今やゐんばぐすの多変量確率分布の関数どももかなりの確信をもって
使えるようになったので,
ECOAS プランクトンデータ解析に応用してみた.
いろいろ試行錯誤してみたんだけど,
本日の結果としてはこんなところか
(事後分布表,
BUGS code).
うーむ.
-
今日もへろへろと撤退.
1820 研究室発.
1840 帰宅.
晩飯の準備.
晩飯.
-
[今日の運動]
-
腹筋運動 30 ×
3 回.
腕立ふせ 10 ×
3 回.
スクワット 100 回.
-
[今日の食卓]
- 朝 (0840):
米麦 0.8 合.
ネギ・ブナシメジの味噌汁.
キャベツ・ニンジン・キュウリ・ネギのサラダ.
キムチ.
- 昼 (1330):
研究室お茶部屋.
米麦 0.8 合.
レトルトパウチドカレー.
- 晩 (1930):
スパゲッティー.
ナス・ピーマン・タマネギ・シイタケのトマトソース.
キャベツ・ニンジン・キュウリ・タマネギのサラダ.
2007 年 09 月 10 日 (月)
-
0830 起床.
ねぼうしてしまった.
朝飯.
コーヒー.
0945 自宅発.
曇.
ちょい雨.
1000 研究室着.
-
昨日のゐんばぐす試行錯誤の報告 (つまりぎょーむ日誌)
書いたり,
放置メイルに返信してみたり.
そして,
回避不可能感のある査読をひきうけてしまったり
……
うーむ,
イヤなかんぢだ.
たまには楽しい査読とかやりたいものですなぁ
……
-
ECOAS プランクトンデータの階層ベイズモデルの改良あれこれ.
-
観測値はそんなに信頼できない,
ということで分散パラメーターの事前分布を修正
-
標高と湖沼面積の交絡のせいで混交が悪くなってる
……
しょうがないので湖沼面積も統計モデル化,
つまりベイズモデルの中で標高補正
湖沼面積の標高補正,
こりゃーいいアイデアだとやってみると
……
なぜかしらかえって劣悪になった.
えーい,
湖沼面積だけでいいや.
どうせ標高が高くなると湖沼面積は小さくなるわけだし.
-
で,
標高ぬいたら収束するまでの時間が激減,
気分もすっきり.
-
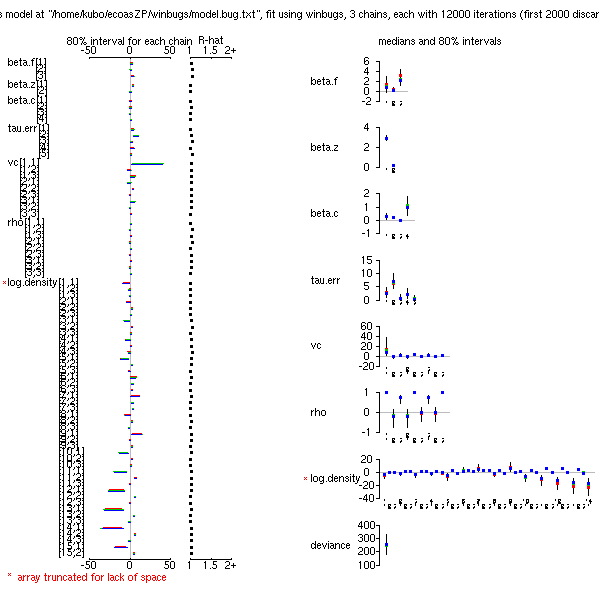
12000 MCMC step (最初の 2000 だけ burn-in)
240 秒ほどで計算終了.
たぶんもっともっと短い計算時間でも十分だろう
(事後分布表).
-
昼飯.
-
ということで,
ここまでの ECOAS プランクトンデータの統計モデリングについて,
占部さんたちに報告かき.
現時点では,
ごくごく簡単な報告ですませるつもりなんだけど,
説明にめんどう感つのる
……
まあ,
どういう説明でもそうなんだけど.
-
二時間ほど費やして ECOAS PukiWiki 上に統計モデル解説メモ書き.
けっこう長くなってしまった.
うう.
東北方面にメイルかき.
ひと休み.
時刻は 1635.
-
revised な
母子里 Gibbs 林冠モデルはどうなったのかしらん,
と思ったらまだ
with Editor どまり,
か.
Agricultural and Forest Meteorology
はこのあたりのんびりしてるのかしらん?
-
論文といえば「アリ」がまだ残存してたな.
早く脱アリしたいんだけど
……
-
じつは ECOAS プランクトンデータ,
まだ動物プランクトンの組成解析をやってないんだよね
……
-
とゆーことで,
よろよろと動物プランクトンのバイオマス組成データなどながめてみる.
-
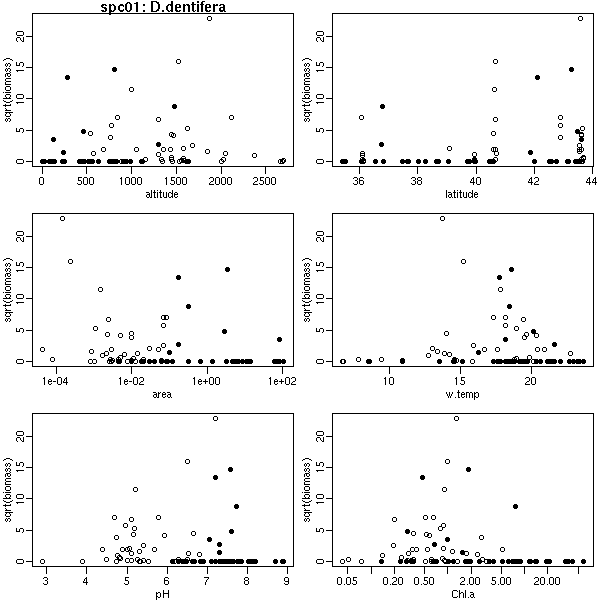
データ変換して,
また「全データが見える作図」
プログラミング.
これは 64 種のプランクトンのうち一種.
-
プランクトンデータながめてるうちに気づいたんだけど
……
サカナって pH が 6 より小さい (酸性の) 湖沼にはすんでないんだな
(動物プランクトンなんかはそういうところにもいる)
……
理由は知らないけど.
R の
glm()
で調べてみたら pH は log(湖沼面積)
より良い説明変数になってた
(そして log(湖沼面積) は標高より良い).
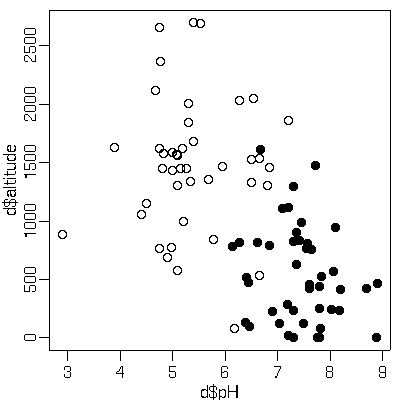
[高山? 低山? の酸性湖?]
えーと,
このあちこち交絡しまくりデータなので注記しておくと,
なぜかしら湖沼の pH は標高が高いほど低くなっている
(酸性になってる).
ということで,
このデータの場合,
標高 1600 m 以上にも魚はいないわけだが.
とはいえ,
pH = 3 というレモン汁みたいな湖は標高 1000 m 以下にあるな.
-
プランクトン 1 種につき 1 ペイジの図セットを 64 ペイジ
PDF 出力する.
R の
pdf() 関数つかえば簡単に
……
しかし,
どうも種ごとに見てもよくわからんなあ.
プランクトンの知識がないからでもあるけれど.
-
空腹になってきたので,
1920 研究室発.
1935 帰宅.
体重 68.4 kg.
晩飯.
-
冷凍庫なき冷蔵庫の製氷棚の氷はがし作業.
3-4 週間に一度ぐらいやってる.
-
今後のぎょーむ予定.
冷静に考えて
-
9 月: ECOAS 下うけデータ解析
(プランクトンと八甲田湿原群)
でオワりそう,
月末に仙台出張??
-
10 月: 日光会議の準備と 11 月統計学授業の準備
-
11 月: 統計学授業やりつつ,脱アリ作文?
ホントはもっと早く脱アリしたいんだけどね
……
そしてフィールド調査の季節がオワると,
いろいろとめんどうな問題がもちこまれるんだろうね.
-
[今日の運動]
-
[今日の食卓]
- 朝 (0920):
米麦 0.7 合.
キャベツ・ニンジン・キュウリ・タマネギのサラダ.
ネギ・ブナシメジ・卵の炒めもの.
- 昼 (1330):
研究室お茶部屋.
米麦 0.7 合.
キャベツ・ニンジン・キュウリ・タマネギのサラダ.
- 晩 (2030):
米麦 0.7 合.
ピーマン・タマネギ・卵炒飯.
キャベツ・ニンジン・キュウリ・タマネギのサラダ.