
[環境科学のための階層モデリング]
詳しい内容は
出版社のペイジ
に.
ペイジ数は 205 と多くはないが
(厚さも 1cm 弱),
内容はひじょうに「アツい」ものがある.
これまでにない本・時代の変わり目,
ということで「画期的」なのかも.
May 10 04:08:45 hosho kernel: hda: dma_intr: status=0x51 { DriveReady SeekComplete Error }
May 10 04:08:45 hosho kernel: hda: dma_intr: error=0x40 { UncorrectableError }, LBAsect=71358237, high=4, low=4249373, sector=27532912
May 10 04:08:45 hosho kernel: end_request: I/O error, dev 03:02 (hda), sector 27532912
/dev/hda
そろそろ買いかえどきかなあ.
ひっこしが面倒だ.
Clark JS and Gelfand A (eds). 2006. Hierarchical Modelling for the Environmental Sciences Statistical methods and applications. Oxford University Press.が届いた.
library(survival)
にある Cox 比例ハザードモデルがうまく適用できてるみたいだな
……
推定されたパラメーターのもとで,
任意の生残曲線を出力するには
survfit()
にあたえる data
を工夫する.
/dev/hda,
今朝もエラーはでてない.
もうちょい様子をみるか.
しかし交換方法は検討しておく必要あるな.
いやはや.
dd
でまるごとコピーするか?
/var/log/messages
に
/dev/hda
またエラーが出てる.
交換すべき時期だよなぁ
……
さて,
どうしたもんだか.
まあ,
backup を毎朝とってるんで,
もしいきなり壊れたとしても問題は少ないと思うけど.
この「ぎょーむ日誌」とかがしばらく見れなくなるだけです.
expression("pollen (" %*% 10^3 * ")")
とすればよい.
ただたんに,
×
は
%*%,
ということだけなんだが
……
%*%,
は expression()
の中においても当然ながら二項演算子として評価されるので,
左右の値を文字列でも何でもよいのでおいてやる
(ただし演算子をおいてはだめ),
そうでないと
「構文エラー」
になる,
というわけで.
perl-5.8
になっても日本語の問題アリ,
か
……
解説原稿,
とりあえず LaTeX で書いてるんだけど,
platex
に渡すまえに自作の簡単な Perl フィルターを通すようにしてみた
(「.」→「。」一括置換などなどのため).
しかし部分的ながら文字ばけやがるンだよね.
use Jcode;
で入力を UTF-8 に変えてもダメか
……
ということで,
チカラわざで Makefile
を
${TARGET}.dvi: ${TARGET}.tex
lv -Ou8 ${TARGET}.tex | ./misc/esjconv.pl | lv -Oej > tmp.tex
mv -f tmp.tex ${TARGET}.tex
platex ${TARGET}.tex
としてみる.
うまくいった.
つまり正解は
Jcode
などに頼らず,
成田さんの
lv
に文字コード変換まかせるべき,
ということか.
(後記:
Perl スクリプト esjconv.pl
は UTF-8 で encode されている必要がある)
(さらに後記:
Perl-5.8.x では
use Jcode;
ではなく
use Encode;
を使うべきだった
……)

dd
して,
とやれば最小手間で交換できるのではなかろうか.
どうだろう.
まあ,
作業するにしても週末とかですかね.
WinBUGS
とかはどんな魔術を使っているんだ?)
use Encode;
してみる.
#!/usr/bin/perl -w
use strict;
use Encode;
my $file = shift @ARGV;
my $lines;
open IN, '<:encoding(euc-jp)', $file or die;
while (<IN>) {
s/./。/g;
... (中略) ...
$lines .= $_;
}
close IN;
open OUT, '>:encoding(euc-jp)', $file or die;
print OUT $lines;
close OUT;
__END__
use Encode;
のかわりに (たとえば)
use encoding 'euc-jp';
としておけば Perl スクリプトじたいが
(この例の場合だと)
EUC-JP で書かれていても動作する,
とのこと
……
実験してみたらたしかにそうなった.
Perl 内部のあつかいは UTF8 なので,
EUC-JP で読みこんで書き出すならば
この場合でも入出力どちらの open にも
encoding(euc-jp) うんぬんが必要である.
png()
device でも問題なく日本語がでる
(ひょっとして以前から問題なかったっけ?)
-2 log[(full モデル尤度) / (いまのモデルの尤度)]なる数量 (residual deviance) が標本数おおくなると自由度 (差) n の χ2 分布 (その平均値は n) に漸近するはず, といったハナシだ. これってホントかよ, というような.
sudo /sbin/e2fsck -y /dev/hda2
……
うむ,
ぼろぼろだ.
修復に時間かかりそう (一時間ぐらいを費した).
あ,
/dev/hda2
のファイルシステムは ext3
か (/etc/fstab で ext2
で mount するよう変更).
しかし fsck.ext3
の実体は e2fsck
なわけで.
-rwxr-xr-x 3 root root 652907 Jun 25 2004 /sbin/e2fsck -rwxr-xr-x 3 root root 652907 Jun 25 2004 /sbin/fsck.ext2 -rwxr-xr-x 3 root root 652907 Jun 25 2004 /sbin/fsck.ext3
/dev/hdb1
と
/dev/hdb2
も e2fsck.
こちらは何の問題もなし.
さて.
optim()
とか使った最尤推定が必要になる.
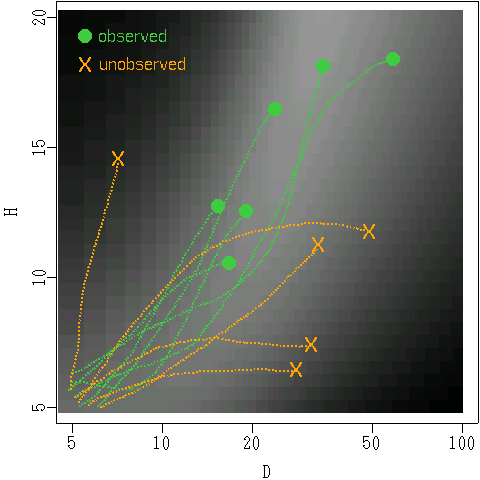
そして母樹の良さや定着地 (倒木) の良さが
random effects だとすると
……
ここが面倒だと例によって Bayes な推定になる,
と.
e2fsck
した
/dev/hda2
を
ext2
にするのを忘れていた.
sudo /sbin/tune2fs -O ^has_journal /dev/hda2
でぢゃーなるファイル削除.
