use Encode;
してみる.
#!/usr/bin/perl -w
use strict;
use Encode;
my $file = shift @ARGV;
my $lines;
open IN, '<:encoding(euc-jp)', $file or die;
while (<IN>) {
s/./。/g;
... (中略) ...
$lines .= $_;
}
close IN;
open OUT, '>:encoding(euc-jp)', $file or die;
print OUT $lines;
close OUT;
__END__
use Encode;
のかわりに (たとえば)
use encoding 'euc-jp';
としておけば Perl スクリプトじたいが
(この例の場合だと)
EUC-JP で書かれていても動作する,
とのこと
……
実験してみたらたしかにそうなった.
Perl 内部のあつかいは UTF8 なので,
EUC-JP で読みこんで書き出すならば
この場合でも入出力どちらの open にも
encoding(euc-jp) うんぬんが必要である.
png()
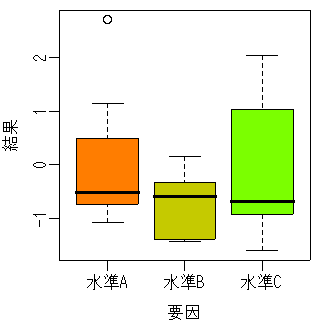
device でも問題なく日本語がでる
(ひょっとして以前から問題なかったっけ?)
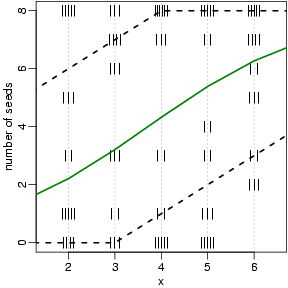
-2 log[(full モデル尤度) / (いまのモデルの尤度)]なる数量 (residual deviance) が標本数おおくなると自由度 (差) n の χ2 分布 (その平均値は n) に漸近するはず, といったハナシだ. これってホントかよ, というような.