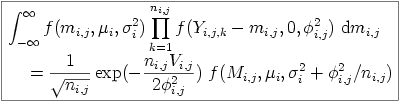
and と書き換えて再投稿.
これで問題ナシ.
| 学部学生 B1 | 6422 円/8 時間 |
| 学部学生 B2 | 6631 円/8 時間 |
| 学部学生 B3 | 6845 円/8 時間 |
| 学部学生 B4 | 7092 円/8 時間 |
| 大学院生 M1 | 7368 円/8 時間 |
| 大学院生 M2 以上 | 7600 円/8 時間 (これが悲しむべき上限額) |
f(., μ, σ2)
が Gauss な確率分布密度で,
Mi,j
と
Vi,j
はそれぞれ小集団ごとの標本平均・標本分散.
Mi,j
と
Vi,j
は十分統計量 (sufficient statistic)
というやつだろうか,
と思ったんだけどそうではなさそうだ.
これらが導かれてきたのは
f(., μ, σ2)
が正規分布であることに強く依存している.
十分統計量なら確率分布にはよらないはず,
と理解してるんだけど
……
うーん,
実は f
が指数関数族なら何でもいい,
ということなら十分統計量と言えるのかもしれんなぁ.
どうなんだろう.
cvs checkout
せんといかんの?
追跡調査が必要.
make dvi && make pdf
してアップロードしておく.
また連絡メイル.
今日はここまで.
usb-storage kernel module).
脱力するほどの簡単さだ
……
というのも,
私のカーネルはそのあたりがなぜかしら
すでにキチンと準備していたもんで,
カーネルまわりの設定変更ゼロ.
mount -t vfat /dev/sda1 /mnt/...,
まぁ,
このへんの詳細はまた後日にでも.
直感的な意味合いとしては, ある確率分布 X を (この問題の場合) 正規分布の代替物として使った場合, どれぐれらいの情報量が損なわれるか, をあらわしたのが KL-divergence (distance) です.と回答してみた (この場合は,あえて正規分布などと書いているけれど, KL-divergence はどんな確率分布にも適用可能), するとまた質問者の原嘉隆さん (九州沖縄農研・土壌) から「情報量ってなんでしょう」 という私信いただいた. こう, 質問されてる内容は 私がちゃんとよく理解してない領域に徐々に近づきつつあるわけだが …… このような説明を書いてみた.



ghostscript-7
のコンパイル (srpm → rpm) に着手してしまった
……
だって,
Vine-Linux 3.0 のリリースがどんどん
遅れて
いるんだよね.
