[ヘンな天気の一日]
いや,
ちょっと晴れたので北大構内走にでようとしたんだけど,
いきなりアラレまじりの大雨になったりして,
ですね
……
今日はホントに天気が不安定な一日だった.
写真は当家から見下ろした国道 5 号線
& 創成川.
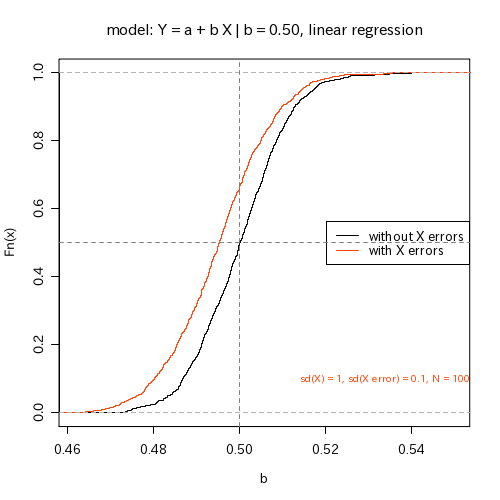
fit.Xnoise <- function(N = 100, sd.X = 0.1, sd.y = 0.1, b.x = 0.5)
{
x <- rnorm(N) # sd.x = 1
X <- x + rnorm(N, 0, sd.X)
y <- rnorm(N, b.x * x, sd.y)
list(
modelx = coef(glm(y ~ x)),
modelX = coef(glm(y ~ X))
)
}
これを 1000 回ばかり繰り返して,
たとえば「傾き」の推定値の分布を図示してみると
……
なるほど,
たしかに「ゆるい」方向に systematic にズレてますな
(これはつまり,
「左右にハミだす」から).
N が大きいほどこのズレが「めだつ」
(推定誤差が小さくなるのに対して).



本日,文部科学省並びに日本学術振興会よりメールがあり, 平成22年度概算要求の見直しにより,以下の2種目について 平成22年度新規課題の公募を停止するとの連絡がありました。 (平成21年度以前の採択課題については継続される予定) ・新学術領域研究(研究課題提案型) ・若手研究(S) 正式な通知は別途行われる予定ですが,取り急ぎ関係者へご周知 いただくようお願いします。

cp1.png と cp2.png)
convert
コマンドで
convert cp*.png cp.pdf
で ghostscript な PDF ファイル (2 ペイジ) を生成





========================================== 【提案受け付け番号】: W-013 【集会種別】: 自由集会 【お名前】: 久保拓弥 様 【所属】: 北海道大・地球環境 【e-mail】: kubo@ees.hokudai.ac.jp 【集会タイトル】: データ解析で出会う統計的問題: 「X の誤差」も統計モデル化 【提案内容】: 今回は説明変数のさまざまな「誤差」について検討したい.たとえば直線回帰 Y = a + b X では「Y の誤差は等分散正規分布」といった仮定をする.しかしながら,「X の誤差」について考慮されることはあまり多くはない.生態学の回帰分析では, X も観測値であるために測定誤差がある場合が多い.また,X が何かの推定値であると きには X の推定誤差を考慮しなければならない.たとえば「X の誤差」によって 傾き b が「ゆるく」なるように推定されることがある.また「X の誤差」を無視す るだけでなく,「X が原因,Y が結果」といえないような状況であっても簡単な線形 モデルが適用されることがあり (例: アロメトリー解析),統計モデルとしてわかり やすくない. この自由集会では,これらの問題の影響と解決策を具体的に議論したい.最初に粕谷 が「X の誤差」を無視したときに生じる推定結果の偏りや ... について紹介する. 次に伊東がベイズモデルによる推定の偏りの補正を検討し, 最後に久保がベイズ統計モデルによって「X の誤差」を明示的に組みこんだ統計モデル の作りかた,あるいは「何でもアロメトリー」にしないための「X と Y の誤差を同 時に考える」統計モデリングの例を紹介したい. 話題提供者: 粕谷英一 (九州大・理) 伊東宏樹 (森林総研多摩) 久保拓弥 (北海道大・地球環境) 【受け付け日時】: Tue Oct 20 09:26:25 2009 ==========================================