help.start()
すると web browser から起動中の R にアクセスする.
R は web server としてふるまい,
リクエストのあった help の HTML ファイルを動的に生成する
(startDynamicHelp).
rsync
で同期して,
R.css をちょっとヒネっただけのもの.
しかし今や静的な HTML ファイルは生成されないので,
package を新しくしても help は新しくならない.
site-library
ディレクトリ (Ubuntu 版だと
/usr/lib/R
と
/usr/local/lib/R
に分散して存在する)
のどこかにある help の Rd
ファイルをさがし,
それを何か
Rd2HTML()
のたぐいで変換することなのだが
……
どこに help データがあるのか,
よくわからん!
00Index.html
ファイル
(例)
は現在でも静的に生成されているので,
これは rsync
でとりこむ.
sudo R
な状態で,
options(help.try.all.packages = TRUE, htmlhelp=TRUE) make.packages.html(temp = FALSE)によって
/usr/lib/R/doc/html/packages.html
が生成されるので,
これも rsync
とかする.
このあたりも自動化.
sudo apt-get install r-doc-html
とかやっとかないと,
この
00Index.html
がインストールされてない場合があったり
……
00Index.html
のリンクからたどってみた.
packageDescription
とかだと,
いろいろわからないこともあるので.
うーむ,
どこかにどの関数の help ファイルはこれこれ,
と対応づけるデータあるはずなんだが.
Sys.sleep(0.1)
とか姑息なブレイキが必要.
dynamicHelp.R
まわりなんかをもっと詳しく調べればいいのかもしれないけど.
options(browser = "/usr/bin/wget -r -nc") help.start()こっちのほうがよっぽど速い. しかし, これでは毎回全ファイルが更新されるんだよね.
fsck.ext3
でとりあえず修復.

1.発表数が2以下の分野は廃止し、第2希望の分野に統合するか、第2希望が廃止分野の場合は第3希望の分野へ統合(ESJ55は、1件のみ第3希望を選択)。にとりくんでみる. 「分野 1, 2, 3」だけがとりあえず必要なのだが,
> d <- d[, c("登録番号", "分野1", "分野2", "分野3")]
としてみる.
> summary(d)
登録番号 分野1 分野2 分野3
Min. : 2 26_生態系管理: 24 25_保全 : 30 00_なし :157
1st Qu.: 254 25_保全 : 20 26_生態系管理: 23 02_植物個体群: 10
Median : 616 21_行動 : 16 20_動物生活史: 16 26_生態系管理: 10
Mean : 626 27_外来種 : 16 15_種多様性 : 15 01_群落 : 8
3rd Qu.: 956 14_進化 : 14 14_進化 : 14 19_動物個体群: 8
Max. :1372 16_数理 : 14 02_植物個体群: 13 20_動物生活史: 8
(Other) :139 (Other) :132 (Other) : 42
えーい,
またかたよってるな.
> g1 <- table(d$分野1) # 発表者数を数えてね
> sort(g1) # 発表者数の少ない順にならべてよ
06_送粉 08_菌類 09_微生物 18_動物繁殖
1 1 1 1
07_種子散布 24_古生態 29_物質生産 23_分子
2 2 2 3
05_植物生活史 12_フェノロジー 20_動物生活史 02_植物個体群
4 4 4 5
04_植物繁殖 11_遷移・更新 28_都市 15_種多様性
6 6 6 7
03_植物生理生態 13_動物と植物の相互関係 22_社会生態 01_群落
8 8 8 9
19_動物個体群 10_景観生態 14_進化 16_数理
10 13 14 14
17_動物群集 30_物質循環 21_行動 27_外来種
14 14 16 16
25_保全 26_生態系管理
20 24
ポスター部会からのもうしいれで,
「口頭発表の分野わけとポスター発表の分野わけが重ならないように」
(ポスター賞の審査員確保のため)
とゆーハナシがあるのだが,
現時点で 13 個以上の発表がある分野は,
発表日数が二日間にまたがることに決定.
このあと,
少数分野廃止 → 移行があるので,
さらにこれは増える可能性がある.
> g1[g1 < 3] # 発表者数が 3 未満のやつはどれかな? 06_送粉 07_種子散布 08_菌類 09_微生物 18_動物繁殖 24_古生態 29_物質生産 1 2 1 1 1 2 2これらのグループは消滅する (第 2 希望以降のグループになる) ことに決定. まあ, やはり前回と同じよーなかんじで.
> levels.g <- levels(d$分野1) > levels.g [1] "01_群落" "02_植物個体群" "03_植物生理生態" "04_植物繁殖" [5] "05_植物生活史" "06_送粉" "07_種子散布" "08_菌類" [9] "09_微生物" "10_景観生態" "11_遷移・更新" "12_フェノロジー" [13] "13_動物と植物の相互関係" "14_進化" "15_種多様性" "16_数理" [17] "17_動物群集" "18_動物繁殖" "19_動物個体群" "20_動物生活史" [21] "21_行動" "22_社会生態" "23_分子" "24_古生態" [25] "25_保全" "26_生態系管理" "27_外来種" "28_都市" [29] "29_物質生産" "30_物質循環"
> d$分野2 <- factor(d$分野2, levels = levels.g) > d$分野3 <- factor(d$分野3, levels = levels.g)こうすると, たとえば, こんなふうに
sapply()
と
table()
のコンビネイションわざでこんなのができるんだよね.
> sapply(1:3, function(k) table(d[, sprintf("分野%i", k)]))
[,1] [,2] [,3]
01_群落 9 12 8
02_植物個体群 5 13 10
03_植物生理生態 8 5 2
04_植物繁殖 6 6 0
05_植物生活史 4 6 2
06_送粉 1 1 1
07_種子散布 2 1 0
08_菌類 1 2 0
09_微生物 1 5 1
10_景観生態 13 9 2
11_遷移・更新 6 5 1
12_フェノロジー 4 5 1
13_動物と植物の相互関係 8 4 3
14_進化 14 14 2
15_種多様性 7 15 3
16_数理 14 9 2
17_動物群集 14 12 5
18_動物繁殖 1 3 4
19_動物個体群 10 13 8
20_動物生活史 4 16 8
21_行動 16 5 2
22_社会生態 8 3 2
23_分子 3 7 0
24_古生態 2 2 1
25_保全 20 30 4
26_生態系管理 24 23 10
27_外来種 16 3 2
28_都市 6 2 0
29_物質生産 2 3 0
30_物質循環 14 4 1
しかしこれは無意味なテイブルだな.
上でやった「levels 変換」はのちのち役にたつのだが.
> # 発表数 3 未満のグループを廃止 > g <- d$分野1 > table.g <- table(g) > removed.g1 <- levels.g[table.g < 3] > removed.g1 [1] "06_送粉" "07_種子散布" "08_菌類" "09_微生物" "18_動物繁殖" "24_古生態" "29_物質生産"今度は 243 人の発表者のうち, 以上の発表グループを第一希望にしてるヒトたちは, と ……
> people.removed.g1 <- g %in% removed.g1 > # 243 名のうち第一希望グループで発表できない人 > sum(people.removed.g1) # その合計 10 名 [1] 10第一希望が通らなかった人たちを第二希望に移動してみる.
> # 第一希望が通らなかった人たちを第二希望に
> g[people.removed.g1] <- d[people.removed.g1, "分野2"]
> sort(table(g))
06_送粉 07_種子散布 18_動物繁殖 24_古生態
0 0 0 0
29_物質生産 08_菌類 09_微生物 05_植物生活史
0 1 1 4
12_フェノロジー 23_分子 02_植物個体群 20_動物生活史
4 4 5 5
11_遷移・更新 28_都市 04_植物繁殖 15_種多様性
6 6 7 7
03_植物生理生態 22_社会生態 13_動物と植物の相互関係 19_動物個体群
8 8 10 10
01_群落 10_景観生態 14_進化 16_数理
11 13 14 14
30_物質循環 17_動物群集 21_行動 27_外来種
14 15 16 16
25_保全 26_生態系管理
20 24
まーたまた昨年と同じく,
「第 1 希望 菌類」
「第 2 希望 微生物」
みたいに,
第 1 希望も第 2 希望も廃止されちゃうグループだったんですね.
はい.
登録番号 分野1 分野2 分野3
26 80 06_送粉 04_植物繁殖 13_動物と植物の相互関係
29 90 07_種子散布 13_動物と植物の相互関係 02_植物個体群
51 201 09_微生物 08_菌類 15_種多様性
58 235 24_古生態 23_分子 19_動物個体群
110 558 07_種子散布 13_動物と植物の相互関係 <NA>
146 767 29_物質生産 01_群落 <NA>
151 790 08_菌類 09_微生物 <NA>
207 1127 24_古生態 01_群落 10_景観生態
211 1152 18_動物繁殖 20_動物生活史 25_保全
230 1267 29_物質生産 17_動物群集 <NA>
> g[51] <- "15_種多様性" > g[151] <- "15_種多様性"と設定して, 集計をやりなおしてみる.
> sort(table(g))
06_送粉 07_種子散布 08_菌類 09_微生物
0 0 0 0
18_動物繁殖 24_古生態 29_物質生産 05_植物生活史
0 0 0 4
12_フェノロジー 23_分子 02_植物個体群 20_動物生活史
4 4 5 5
11_遷移・更新 28_都市 04_植物繁殖 03_植物生理生態
6 6 7 8
22_社会生態 15_種多様性 13_動物と植物の相互関係 19_動物個体群
8 9 10 10
01_群落 10_景観生態 14_進化 16_数理
11 13 14 14
30_物質循環 17_動物群集 21_行動 27_外来種
14 15 16 16
25_保全 26_生態系管理
20 24
これでめでたくどのグループも発表数が 4 以上になった.
> table.g <- table(g) # 再計算 > removed.g <- levels.g[table.g == 0] > removed.g [1] "06_送粉" "07_種子散布" "08_菌類" "09_微生物" "18_動物繁殖" "24_古生態" "29_物質生産"243 人分の確定「発表グループ」の水準つけなおし (30 水準から上の 7 個を除いた 23 水準) はこれでよい:
> g <- factor(g)
> table(g)
01_群落 02_植物個体群 03_植物生理生態 04_植物繁殖
11 5 8 7
05_植物生活史 10_景観生態 11_遷移・更新 12_フェノロジー
4 13 6 4
13_動物と植物の相互関係 14_進化 15_種多様性 16_数理
10 14 9 14
17_動物群集 19_動物個体群 20_動物生活史 21_行動
15 10 5 16
22_社会生態 23_分子 25_保全 26_生態系管理
8 4 20 24
27_外来種 28_都市 30_物質循環
16 6 14
> sort(table(g))
05_植物生活史 12_フェノロジー 23_分子 02_植物個体群
4 4 4 5
20_動物生活史 11_遷移・更新 28_都市 04_植物繁殖
5 6 6 7
03_植物生理生態 22_社会生態 15_種多様性 13_動物と植物の相互関係
8 8 9 10
19_動物個体群 01_群落 10_景観生態 14_進化
10 11 13 14
16_数理 30_物質循環 17_動物群集 21_行動
14 14 15 16
27_外来種 25_保全 26_生態系管理
16 20 24
243 名の発表者の皆さんの発表グループ確定.
めでたしめでたし.
> as.matrix(table(g)[table(g) > 12])
[,1]
10_景観生態 13
14_進化 14
16_数理 14
17_動物群集 15
21_行動 16
25_保全 20
26_生態系管理 24
27_外来種 16
30_物質循環 14
いまごろゑくせる上でポスター分野わけに苦闘しておられる
関さんにあらかじめのご注進におよんでみますか.
久保です.口頭発表の分野わけの準備のため,データを いろいろと調べているところですが,第 1-3 希望などを 調節してみたところ,以下の分野で 10_景観生態 13 14_進化 14 16_数理 14 17_動物群集 15 21_行動 16 25_保全 20 26_生態系管理 24 27_外来種 16 30_物質循環 14 発表数が 12 をこえていました.これらの分野では口頭発表 の日程が二日以上になります.つまり,これらの分野では 口頭発表とポスター発表の日程が重なりそうです. 発表数 13-14 のところは何人かポスターに移動していただい て一日におさめることが可能かもしれません (口頭発表数合計 が 243 なので,現状の会場わくでは収容できないので). しかし発表数が現状で 15 をこえている分野では,必ず二日に またがるものと考えたほうがよさそうです.
久保です.口頭発表会場・発表時間帯について,ちょっと お尋ねしたいことがあるのですが…… 私の予想「口頭発表数は東京大会で 203 だったから,札幌 も同じぐらいだろう,全体で 240 発表ぐらいの部屋・時間 わくを確保しておけばだいじょうぶだろう」……がくつが えされてしまって,口頭発表数は 243 になってしまいまし た. 現在,口頭発表からポスターに移動していただく人を探し ている最中なのですが,発表数が 240 以下になっても, ある会場では (発表分野ごとの発表数のばらつきの関係な どで) 3 時間×2 日間の発表わくをはみだす可能性があります. そこであらかじめ教えていただきたいのですが…… 口頭発表のいくつかの会場で,08:45 開始とか 12:15 終了, といった開始時間の変更は可能でしょうか.皆さんのご意見 をお聞かせください.

hosho
のシステムを自滅的にぶっこわしてしまった.
これには以前からの惰性で,
Vine Linux 4.2 をいれてたのだけど,
ring server の下をつらつら見てたら
「お,5.2 があるぢゃん」
とか思って /etc/apt/sources.list
をちょっと書き換えて
apt-get
してしまったのだが
……
ぢつは 5.2 って beta3 ぢゃん!
apt-get
でやるとだいたいコケるのだが
……
ぎょーむ日誌にそういう苦闘の記録があるはずだけど,
もはや検索する気にもならづ.

hosho 修繕中]
$ nmap 192.168.1.20 Starting Nmap 5.00 ( http://nmap.org ) at 2010-11-18 15:55 JST Interesting ports on 192.168.1.20: Not shown: 995 closed ports PORT STATE SERVICE 23/tcp open telnet 80/tcp open http 515/tcp open printer 631/tcp open ipp 9100/tcp open jetdirect
8F 植物生態の久保です.ちょっと,A710 室のネットワーク について相談させてください. A710 南側ドアのそばにあるプリンター Brother HL-5380DN に ついて * さんから「他の階からも使用したいので,IP アドレス を (A7-8F ネット管理者の久保が) とってほしい」という依頼を うけました. ようするに他の階から A710 のプリンターで印刷できればいいん だろう,と考えて昨日いろいろとネット設定の工夫をしてみたの ですが,他の階から印刷させる設定は不可能でした. ということで,次なる策として,A7F の配線を組みかえて,A710 内の * 研の皆さんを北大ネットに直接接続する計画を考えていま す.プリンターも北大ネットに直結になりますので,どこからでも 利用可能になりますので. おそらく A710 移動以前は皆さん直接に北大ネットにつなげておら れたと思いますので,このように変更して問題ないように考えてい るのですが,いかがでしょうか.ご意見いただけると助かります.まあ, これでしばらく放置しとこう.
hosho
の様子を調べる
……
うーむ,
proftpd
(これも捨てたいしくみだ)
に不正なアクセスがあるなぁ.
Nov 19 10:22:01 hosho proftpd[9041]: hosho.ees.hokudai.ac.jp (::ffff:218.106.246.114[::ffff:218.106.246.114]) - FTP session opened. Nov 19 10:22:12 hosho proftpd[9042]: hosho.ees.hokudai.ac.jp (::ffff:218.106.246.114[::ffff:218.106.246.114]) - FTP session opened. Nov 19 10:22:24 hosho proftpd[9045]: hosho.ees.hokudai.ac.jp (::ffff:218.106.246.114[::ffff:218.106.246.114]) - FTP session opened. Nov 19 10:22:36 hosho proftpd[9047]: hosho.ees.hokudai.ac.jp (::ffff:218.106.246.114[::ffff:218.106.246.114]) - FTP session opened. Nov 19 10:22:47 hosho proftpd[9048]: hosho.ees.hokudai.ac.jp (::ffff:218.106.246.114[::ffff:218.106.246.114]) - FTP session opened. Nov 19 10:22:59 hosho proftpd[9049]: hosho.ees.hokudai.ac.jp (::ffff:218.106.246.114[::ffff:218.106.246.114]) - FTP session opened.以前につくった
/sbin/iptables
設定 bash スクリプトを使って 218.106.246.*
からのアクセスを「暗黒の深淵」に DROP
する設定をしてみる.
$ sudo /sbin/iptables --list Chain INPUT (policy ACCEPT) target prot opt source destination ACCEPT all -- anywhere anywhere DROP all -- 218.106.246.0/24 anywhereちゃんと設定できてるようだが ……
Nov 19 10:24:21 hosho proftpd[9089]: hosho.ees.hokudai.ac.jp (::ffff:218.106.246.114[::ffff:218.106.246.114]) - FTP session opened. # この時刻に iptables 再起動 Nov 19 10:29:21 hosho proftpd[9089]: hosho.ees.hokudai.ac.jp (::ffff:218.106.246.114[::ffff:218.106.246.114]) - Session timed out, disconnected Nov 19 10:29:21 hosho proftpd[9089]: hosho.ees.hokudai.ac.jp (::ffff:218.106.246.114[::ffff:218.106.246.114]) - FTP session closed.おお, うまくいった.
sudo /etc/init.d/avahi-daemon stop
して
sudo /sbin/chkconfig avahi-daemon off
しておく.
単能
web server 機には
Avahi
いらない?
以前
にも同じよーなコトやってるな.
3.口頭発表のファイル
受け付けたファイルの管理は実行委員会(久保)が担当する.
以下の手順が確認された.
(1)久保がファイルをダウンロード
(2)バイトによる内容の確認(詳細な動作確認はしない)
確認は1本5分として 20.5時間 あれば 確認可能.
(3)不良ファイルは著者に差し替えを求める(久保)
(過去に不良ファイルが何本くらいあったかを確認:齊藤)
(4)ファイルを会場ごとに発表順にそろえて CD に保存する
(5)3月8日に会場でレンタルPCにインストールする
発表者に伝えること
(1)ファイル提出締切は3月1日
(2)提出先は竹中さんに確認
(3)ファイルサイズは 20メガバイト以下
(4)ファイル形式は PowerPoint or PDF (ヴァージョンは
レンタルPCのソフトを確認後に決める:齊藤)
(5)ウィルスチェックの要不要をレンタル会社に確認する(齊藤)
(6)アニメ,動画ついて制限は設けない(何もいわない)
(7)会場に動作確認の閲覧室を設ける.閲覧の結果,差し替えを
求められても原則として応じない.ただし,発表が困難だと判断
された場合は例外的に対応する(バイトチェック漏れ).
ま,
暫定的な内容なんで,
マにうけないでください.

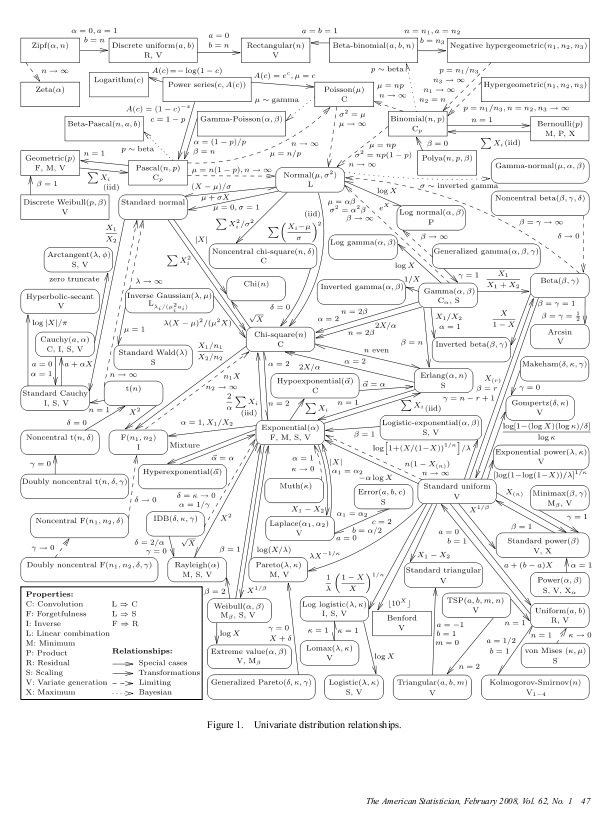
統計学で用いられる「確率分布」の分類に関する話題です. Lawrence M. Leemis and Jacquelyn T. McQueston Univariate Distribution Relationships. The American Statistician, Vol.62, No.1, pp.45-53, February 2008 DOI: 10.1198/000313008X270448 pdf: http://www.math.wm.edu/~leemis/2008amstat.pdf 統計学の世界では数多くの「確率分布」が利用されている. 正規分布や二項分布のようなビッグネームもあれば,聞い たこともない人名が付された確率分布もある.本論文はこ れらの確率分布を平面マップ(あるいは系統ネットワーク) として描かれたチャートによって体系化する試みである. 本論文は現在ではpdfで自由にダウンロードできるが,同 論文の「紙」版には,付録としてこのチャートの折込プレ ートが別に添付されていた.この図表はパラメトリック統 計学の基礎になる確率分布間の相互関係を鳥瞰するととも に,“正規分布帝国”における従属関係を知る上でも便利 だ. Leemis によるこの確率分布の平面マップは,四半世紀前の 1986年にすでに同誌に発表されていた: L. Leemis 1986, Relationships among common univariate distributions, The American Statistician, 40: 143-146. John D. Cook の記事: John D. Cook's blog: The Endeavour, Probability distribution relationships (20 February 2008) http://www.johndcook.com/blog/2008/02/20/probability-distribution-relationships/ は, Leemis のこのチャートは統計学者にとっての「元素 周期律表」であると賞賛している.なお,Cook はこの論文 に基づく確率分布のクリッカブル・チャートを別サイトで 公開している: John D. Cook, (12 October 2008) Clickable diagram of distribution relationships http://www.johndcook.com/distribution_chart.html この図もまた教材としての利用価値は高い. さらに調べてみると,同じような目的で確率分布の間の 「類縁関係」を考察した研究がほかにもあることがわかる. たとえば下記の論文がある: Yousry H. Abdelkader and Zainab A. Al-Marzouq 2004. Probability Distribution Relationships. International Journal of Basic and Applied Sciences IJBAS-IJENS, Vol.10, No.1, pp.76-86. pdf: http://www.ijens.org/1001-91310-3434%20IJBAS-IJENS.pdf パラメトリック統計学での離散型あるいは連続型の「確率 分布」は,確かに統計学者にとって不可欠のツールである. それと同時に,これほど多くの確率分布が導出され,広く 利用されていることを考えるならば,これから統計学を学 習しようとする者のみならず,統計学を生業とする研究者 にとっても,確率分布群の適切な「分類体系化」は不可欠 だ. Leemis をはじめとする確率分布の「平面マップ」による体 系化は,「分類学的精神(la raison classificatoire)」 (Patrick Tort, 1989)が統計学の世界にも受け入れられ てきたことの証といえるだろう. To classify is human.
三中信宏です.いい週末を過ごしてます? 百聞は一聴に如かず.どーぞ! 「ミクの歌って覚える統計入門」 http://miku.motion.ne.jp/ VOCALOID 初音ミクの歌のパワーで、統計の基礎を楽しく 学んじゃおう。 もうつまらない教科書はいらない! 本川達雄『歌う生物学』の伝統を受け継ぐ?『歌う統計学』! ※今日は朝からネタが豊富だなあ.ねんのため書いておきますが, biometry はふだんはほとんど何も投稿のない 静かな mailing list です.
{kind=link}