glmmML()
はデータの欠測にヨワい.
たぶん,
応答変数・説明変数のどちらか一方でも NA
があればダメなのだろう.
library(lattice)
の
barchart
しつもん.
たとえば,
このような架空データ
data05.csv
といったファイルをよみこんで,
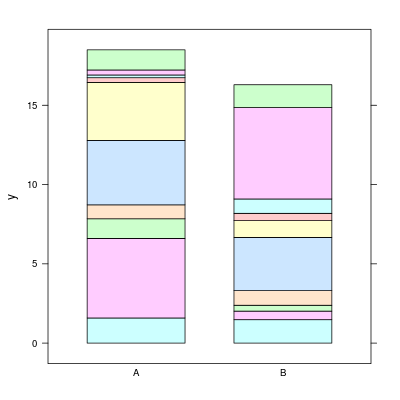
「つみあげぼうグラフ」とやらを書きたければ,
以下のようにできるだろう.
> d <- read.csv("data05.csv")
> head(d)
x y z
1 A 1.58649 1
2 A 5.01285 2
3 A 1.24178 3
4 A 0.88056 4
5 A 4.06050 5
6 A 3.66314 6
> summary(d)
x y z
A:10 Min. :0.173 Min. : 1.0
B:10 1st Qu.:0.521 1st Qu.: 3.0
Median :1.149 Median : 5.5
Mean :1.740 Mean : 5.5
3rd Qu.:2.029 3rd Qu.: 8.0
Max. :5.762 Max. :10.0
> library(lattice)
> barchart(y ~ x, data = d, groups = z, stack = TRUE)
scales = list(y = list(...))
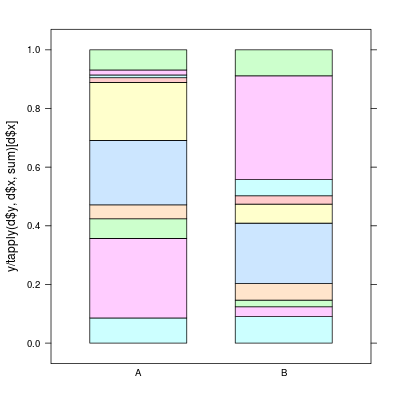
といった指定になるはずなんだけど,
相対化するとかそういうオプションはない.
tapply() わざでも使うしかないだろう.
> barchart(y / tapply(d$y, d$x, sum)[d$x] ~ x, data = d, groups = z, stack = TRUE)
plot(xtabs)
とかかな?
(参照: 2012 年 ESJ 「分割表」自由集会の
投影資料 PDF)
……
これはタテだけでなくヨコまで割算にするという意外な手法で,
情報を「すこしでも多く生き残らせている」うまい例.




