|
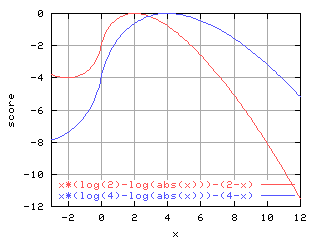
[Quasi-score 関数]
てきとーに書いたもの. 分散∝平均モデル. |
apt-get install した
Canna 3.6p1
の設定.
この Unix 系その他 OS 用の free かな漢字変換サーヴァー
Canna では個人別頻度学習ファイルの使いまわしはできないんで
……
for dic in `lsdic`; do rmdic $dic; done
で古い頻度学習ファイルを捨てる
for dic in `lsdic -i`; do mkdic -fq $dic; done
で新しい頻度学習ファイルを作る
cat usr1.ctd | mkdic - user
退避しておいたユーザー辞書を使って
新しいユーザー辞書の初期化
/usr/doc/Canna*/README.*
や
/var/lib/canna/dic/canna/dics.dir
など見ながら
$HOME/.canna
の辞書指定を変更
(iroha やめて
gcanna,
gcannaf にするとか)
kinput2
を止めて再起動
(KTerm とかも再起動しなくては
…… Rxvt は再起動しなくてよい?)
Spreadsheet::ParseExcel
報告のぎょーむ日誌書き.
prunusdb.pm,
すでにホネぐみはできてるんだけどねぇ.
glm で
family = quasi(link = "log", variance = "mu")
というふうに指定して推定計算させてみる.
dataset <- scan("sample.txt", list(x = 0, y = 0))
dataset <- list(
x = dataset$x,
y = dataset$y,
logx = log(dataset$x),
sqlogx = log(dataset$x)^2
)
quasimodel <- glm(
y ~ 1 + logx + sqlogx,
family = quasi(link = "log", variance = "mu"),
control = glm.control(maxit = 20, trace = TRUE),
data = dataset,
start = c(-2.0, 1.0, 0.2)
)
summary(quasimodel)
R の根性が欠落してるためか,
glm
はこの状況では推定値を収束させることができないようだ.
R の
glm
を使ってうまくいったのは
……
なるほど,
実験してみると平均値に関するモデルが
単調な増加関数だったりすると,
わりとうまく推定してくれるみたいだなぁ.
ところがあのわがままなるカエデの成長はふにゃふにゃしてるんだよねえ.
mlfitting
でこの問題が解決できるんでは,
という見とおしが多少よくなった.
2100 帰宅.
体重 73.6kg.
うーむ減らん.
|
|
[Quasi-score 関数]
てきとーに書いたもの. 分散∝平均モデル. |
mlfitting
の
plugin_function.cc
を書けば自分で計算できそうだ,
ということで取り組んでみる.
|
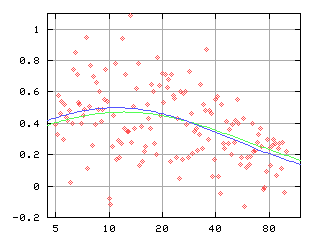
[Quasi-likelihood 推定]
非等分散正規分布 (分散 = 0.25 × 平均) な乱数集団への mlfitting
による非線形モデルのあてはめ
(quasi-score の最大化).
青線が推定結果で緑線が真の平均.
|