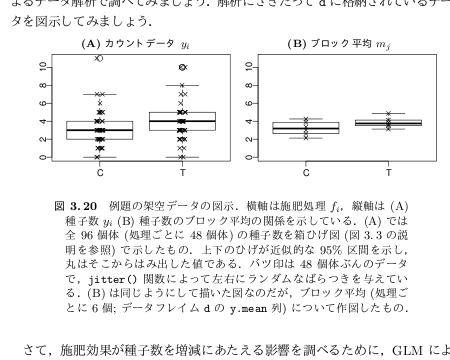
つまりカウントデータセットをこんなふうにブロックにわけて
f block y.1 y.2 y.3 y.4 y.5 y.6 y.7 y.8 y.mean
1 C block01 2 7 2 1 3 2 2 2 2.625
2 C block02 6 4 3 5 3 2 0 1 3.000
3 C block03 3 3 3 3 2 2 0 1 2.125
4 C block04 1 3 5 4 5 11 3 2 4.250
5 C block05 2 3 5 1 5 4 7 4 3.875
6 C block06 4 3 1 3 5 4 3 4 3.375
7 T block07 5 8 7 3 1 5 4 0 4.125
8 T block08 5 3 2 3 2 4 4 2 3.125
9 T block09 5 5 5 3 4 2 4 3 3.875
10 T block10 0 2 1 3 3 7 10 2 3.500
11 T block11 4 3 3 5 2 4 3 5 3.625
12 T block12 5 6 4 3 4 10 3 4 4.875
これを正規分布モデルで解析するとは,
すなわちブロック平均の差を調べます
(等分散性を仮定しつつ),
とゆーことで.