ぎょーむ日誌 2009-03-15
2009 年 03 月 15 日 (日)
-
0830 起床.
生活周期,
またずれぎみ.
朝飯.
コーヒー.
体温
36.7°C,
とくに問題ナシ,
かな.
まだアタマがちょっとぽーっとしてる
……
といった口実をおもいついたので,
すこしばかり怠業.
-
1030 自宅発.
曇.
気温は高い.
札幌駅の本屋をふらふらしたり,
お茶を買ったり.
1110 研究室着.
-
ちょっとまたデータ解析こんさるメイルかき,
とか.
-
ベイズカエル本の第 10 章の
感想
とか書いてて,
ふと気づいたんだが
……
まあ,
この章で使われているタイプの主観事前分布は
できるだけ使わずにデータ解析したいところなんだけど,
毒をもって毒を制する,
ともうしますか,
甲山さん的な「説明変数の濫用」に対抗するには,
こういった主観事前分布をあえて使ってみせる,
もっと言えば「主観事前分布を階層的な事前分布で生成する」
といった方式が使えるかも,
と気づいた.
-
ハナシの経緯はこうなる.
(今年度ではなく)
昨年度の甲山さん M2 院生 3 名のデータ解析は
階層ベイズモデルを初めて本格導入して,
(これまた「甲山さん的な」としかいいようのない)
多樹種系のめんどうにとりくんだ.
で,
苦闘をカサねて
ひととーりなんとか解析できた
……
と安心した矢先,
3 つのモデルのうち 2 つまでが甲山さんの指示による
「汚染」
というかですね,
ふつーに考えて因果関係が言えそうにない
「説明変数」を組みこまれてしまって,
ですね.
まあ,
統計モデルも推定計算も推定結果も
なんだかヘンてこなものになってしまったわけですよ.
-
このあたりは (一部の) 熱帯生態学データ解析にみられる
悪しき習慣,
つまり相関関係をきちんと定量化すればいいのに,
めんどうだから因果関係にする (説明変数にしちまう)
といった作法なんだよね.
-
昨年度のうちになんらかのテをうてば良かったのだが
……
相関関係を推定しようとすると,
これらの問題の場合には,
二変量正規分布を事前分布をやたらと推定してみせなくてはならないし
(これの推定計算はなかなかたいへん),
そもそもこれらの説明変数の正体ってのが
「人間がてきとーにカテゴリーわけした樹種ごとの耐陰性」
「めまいがするほどいいかげんな高次モーメント統計量」
「ある基準に従ってずらずらと並べた樹種の順位 (ある時点での)」
といったもので,
こんなものをどうやって
二変量正規分布なんかと対応づけりゃいいのか,
と.
-
で,
McCarthy のカエルベイズ本の第 10 章「主観事前分布」
にもどるわけだが
……
この章であつかってるような
「みんなにアンケート
(例: 森が伐採されると鳥 A, B, C 種それぞれの存続に
どのぐらいいんぱくとがありますか?)
して事前分布を決めました」
といった態度はどうよ,
と思うのだけど
……
この
「アンケート」→「主観的事前分布をでっちあげる」
といった定式化というか数量的操作の手口について考えてみると,
ここで階層ベイズモデル的な発想が使えるかも,
という気もしてきた.
つまりその「あんけーと」とやらの結果が観測データの説明に使えるのではあれば
事前分布が自動的に「狭く」なり,
うさんくさければ
(超パラメーターである)
分散パラメーターを大きくして無情報事前分布にしてしまう,
と.
-
つまり,
うさんくさいものをこねあげて事前分布たち
(その中には無情報事前分布も含まれる)
をでっちあげる,
という操作に超パラメーター・超事前分布を援用できるのであれば,
上述の多樹種系の解析における
「人間がてきとーにカテゴリーわけした樹種ごとの耐陰性」
「めまいがするほどいいかげんな高次モーメント統計量」
「ある基準に従ってずらずらと並べた樹種の順位 (ある時点での)」
といった因子・数量をこねこねして事前分布を作るといったことができ,
そこに階層ベイズモデル的な考えかたをいれることで
(モデル選択というほどきちんとしたものではないにせよ)
何らかの意味で多少はマシなものになるかもね,
と.
-
えーと,
じつのところ,
モデル中の「ケガれた説明変数」
を因果関係として組みこもうが,
主観的事前分布をでっちあげるところに使おうが,
「統計モデルとしての悪さ」
はあまりマシにはならないかもしれない.
とくに,
上述の多樹種系解析は線形予測子にすべての説明変数をくみこんでいるので,
「説明変数としてほうりこむ」
と
「(「切片」とかの?) 事前分布を作るときに使う」
の本質的な差位はほとんどない場合もある.
-
しかしながら,
「統計モデルの説明」
としては多少はマシになりそうだ.
たとえば,
「人間がてきとーにカテゴリーわけした樹種ごとの耐陰性」
をそのまま説明変数としてほうりこんだりするのではなく,
このてきとーなる因子どもから「主観的事前分布を作り」
(階層ベイズ的な発想の助けを借りつつ)
その主観的事前分布にもとづいて事後分布を算出しました,
と書いて説明したほうが「どのあたりがアヤしいのか」
がわかりやすい.
因果関係のアヤしい因子・数量データを使って観測データを
説明したいので
「残念ながら主観的事前分布をもちださねばなりません」
といった態度を明確にできている.
ケガれた部分とそうでない部分が分離されている,
ように見える.
-
むろん,
査読者が「主観的事前分布なんて自然科学の研究ではありえん」
といった理由で論文を却下するかもしれないけど,
それはまた別の問題だ.
-
ここ半年ほどで気づいた「主観事前分布」のつかいみち:
-
アヤしい「事前情報」とやらを使わざるをえないとき:
上述でくだくだしくうだうだとのべてるとーりですが
(うん? 誰もふぉろーできてない?),
ベイズカエル本の McCarthy と異なるのは,
主観的事前分布をでっちあげるときに
階層ベイズモデル
(階層的な事前分布)
といった考えかたなんかを何か利用できないだろうか,
と検討しているあたり
-
測定誤差のモデリング:
測定誤差と「個体差」の区別がつかなくて困るときは,
測定誤差の大きさを主観的に「えいやー」と決めてしまう
(あるいは測定機器のマニュアルなどにかいてある「精度」
を信じる),
といった方法をとらざるをえない
-
これがイヤなら (少なくとも一部の)
標本を二度以上独立に測定
してください
-
蛇足なンだけど
……
測定精度がどーのこーの
といったハナシが好きなヒトいますけど,
拝聴していると
「なんだか精密に測定できてるみたいでウレしい」
といった気分的なコトが重要であるらしく,
データ解析への定量的な影響とか統計モデルの中でのとりあつかい,
といったことはあまり念頭にないような
……
-
McCarthy のベイズカエル本
(さきごろ野間口さんによる訳本
「生態学のためのベイズ法」
がでた),
この本に紹介されてるいろいろな「事前分布のきめかた」
なんかで
ベイズ統計モデリングをやりたくはないんだけど
……
しかし,
ここまで自分の方法とずれていると,
期せずしていろいろ考えさせる本になっているなぁ,
と.
実際のところ,
必ずしも皮肉というわけでもなく,
やくにたちました.
今後は急増すると予想される
McCarthy 亜流なべいぢあん対策についてもいろいろ検討できた.
-
昼飯.
-
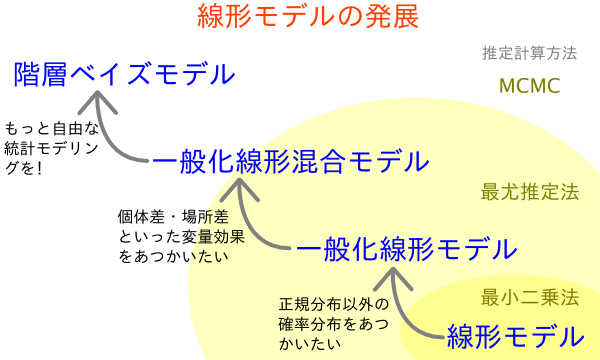
GLM 自由集会の準備のつづき.
「いつもの図」
を整理 & 簡素化してみる.

-
いや,
ここからは
「推定方法」のハナシはいっさい削除すべきか?
-
で,
推定方法その他はこういうふうに図示してみる,
と.
-
まだまだ改訂が必要だろうなぁ,
と危惧しつつも
……
1955 研究室発.
2020 帰宅.
晩飯の準備.
晩飯.
-
[今日の運動]
-
[今日の食卓]
- 朝 (0900):
米麦 0.6 合.
キャベツ・キュウリ・ネギ・ハムのサラダ.
- 昼 (1300):
研究室お茶部屋.
米麦 0.8 合.
麻婆豆腐.
- 晩 (2130):
米麦 0.8 合.
ネギ・シュンギク・シイタケ・カジカの鍋もの.