ぎょーむ日誌 2005-03-02
2005 年 03 月 02 日 (水)
-
0710 起床.
朝飯.
コーヒー.
朝から苫小牧 parasitoid プログラムの修正.
0800 自宅発.
曇.
0810 研究室着.
-
昨晩は Dell 機で,
苫小牧 parasitoid 問題を少し簡単にしたのをやらせてみた.
寄生率が近傍寄生個体密度 (その樹冠,同樹種他個体,他樹種)
だけできまる,
という 4 パラメーターモデルである.
計算させてみると,
やはり 3 時間ちょっとかかる.
ということで maximum pseudo likelihood estimation
(MPLE)
そのものが律速ではないのか
……
(これは本日午後には必ずしも正しくない,
とわかった)
-
講座の web server たる
hosho
のファイルシステムが一部不調らしい,
ということがわかったので,
reboot ついでに e2fsck
させてみる
(reboot すんのは前の停電いらい 143 日ぶり)
……
やっぱり問題あるよーで.
けっこう酷使されてるからなぁ.
時間かかる.
バックアップ用ドライヴだけを reboot 前に check
しとけばよかった.
-
復旧におよそ一時間を費してしまった.
HDD の点検・修復は時間がかかる.
1104 運転再開.
-
待ち時間おちつかなかったので,
おもわずかとーオフィスの掃除をしてしまった.
-
しかしそれはすぐに終了したので,
A801 の Dell 機に ssh して,
ぱいぷ樹木
したうけ計算の準備.
c_wp_length
を 25.0 → 0.0 としてみる.
その意図はシュート形成が
枝先の水ポテンシャルに左右されない,
という状況だ
(とゆーよーなことを計算しろ,
といわれた).
1035 計算開始.
-
苫小牧 parasitoid 問題.
簡単化した GLM ロジスティックモデルで推定される
「同樹種他個体の影響」「他樹種の影響」
の「樹木いれかえ randomization」な MPLE を図にしてみる.
標本数があるていど大きければみょーな交絡もでないよーで,
めでたいことだ
……
本数の少ない樹種 (オオモミジとか)
だと「しましま」ぎみに分布しがちではあるけれど.
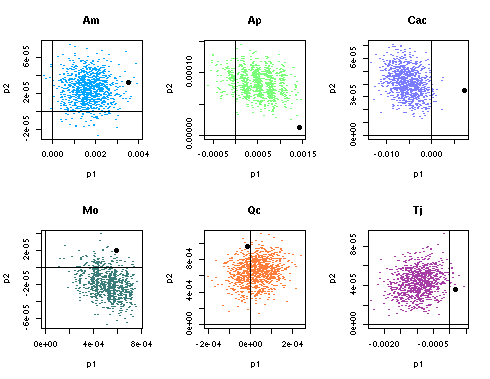
-
とはいえ randomization やってんのに,
推定値がゼロゼロからずれる,
というのは少し気になるんだが.
MPLE ってそういうものなのかしらん?
そういう気もする
……
(約 60 分後に計算プログラムにバグみつかる
--- この図の修正版は翌日に掲載)
-
蛇足ながら,上の作図は
R
上のコマンドライン一行で書こうとしたら
(Perl の one-linear 的発想,とゆーか),
どんどん長くなってわけのわからないものになってしまった.
すごく読みづらい R コードの悪例
ということでここに示してみる:
par(mfrow = c(2, 3)); for (s in c("Am", "Ap", "Cac", "Mo", "Qc", "Tj")) { r <- results[[s]]; p1 <- r$rand.tree[,"p1"]; p2 <- r$rand.tree[,"p2"]; xp <- r$mple$coefficients[["p1"]]; yp <- r$mple$coefficients[["p2"]]; plot(p1, p2, xlim = range(c(0, p1, xp)), ylim = range(c(0, p2, yp)), main = s, pch = "-", col = col.Sp[[s]]); abline(h = 0); abline(v = 0); points(xp, yp, pch = 19) }
……
ながめてるうちに貧乏性が発動して,
けっきょくこのコードも整理整頓して,
関数定義ファイルにおさめてしまった.
-
で,
randomization 関数とかみなおしてるうちに,
上述のばぐとか見つけたり.
まあ,
「ばぐゼロではないだろう」
とは予想してたけれど.
-
昼飯.
講座内にインフルエンザ蔓延.
-
この randomization 計算の高速化に取りくんでみる.
現時点では,
全季節・全種 50 回の試験運転で
> system.time(run.mple.rand(n.trials = 50, v.season = as.integer(1)))
# reading data/data1.txt ...
# calc dist in plot0 ...
# calc dist in plot1 ...
# calc dist in plot2 ...
# calc dist in plot3 ...
# calc dist in plot4 ...
# Randomizedation: host
# trial Am: [0][5][10][15][20][25][30][35][40][45][50]
# Randomizedation: tree
# trial Am: [0][5][10][15][20][25][30][35][40][45][50]
...(中略)...
# Randomizedation: host
# trial Tj: [0][5][10][15][20][25][30][35][40][45][50]
# Randomizedation: tree
# trial Tj: [0][5][10][15][20][25][30][35][40][45][50]
# save to output1.RData ...
[1] 143.53 0.11 143.84 0.00 0.00
143 秒かかる.
また overhead を削るような努力をすこしやってみると,
> system.time(run.mple.rand(n.trials = 50, v.season = as.integer(1)))
...(中略)...
[1] 138.35 0.27 138.65 0.00 0.0
うーむ,
計算時間があまり短縮されん
……
(30 分経過)
……
ふと正気にかえると,
assign(..., env = .GlobalEnv)
などなど
呪われワザ
を濫用した禁断の高速化ワザの世界に踏みこんでしまっていた.
randomization の過程でどうしてもデータの copy
が発生してしまう,
とわかったので正気を見失いがちな高速化計画はすべてほうりだす.
バックアップをたぐって元にもどす
(上述の 138 秒だしたところまで).
R の内部処理,
というのがいまいちよくわかっていないんだが
……
私の現時点での憶測としては,
-
関数にはまず参照でオブジェクトが渡される
(ホントか?
つねに値わたし,
というハナシもある)
-
しかし関数内で渡したオブジェクトを
変更する操作があると,
そのオブジェクトの copy が作られ,
それに改変がくわわる
(もとオブジェクトは変更されない)
といったあたりか.
うーむ
……
ドキュメント読んだほうがいいんだろうけど.
だれか ``Effective R'' を書いてほしい.
高速化うんぬんはいったんおいといて
……
それよりやるべきことは,
まずモデルの単純化ではないか,
ということで
……
寄生 host 密度のみを使ったモデルに変更してみる.
上と同じ条件で計算させると
……
> system.time(run.mple.rand(n.trials = 50, v.season = as.integer(1)))
...(中略)...
[1] 90.72 0.07 91.02 0.00 0.00
結果としてかなり高速化されてしまった.
これはどうも maximum pseudo likelihood
最大化計算でてこずっているゆーより,
距離カーネル加重密度計算で苦闘してる部分も大きいようだ.
昨晩やらせてた計算では,
使いもしない非寄生 host 密度の行列計算が残存していたので,
高速化されなかったのかもしれない.
午前中から始めた
ぱいぷ樹木計算,
4 時間かかって終了.
作図の変換計算ですこしてこずる
……
が無事に下の図のよーにヘクタールあたり
10-20 トンという妥当そうな (?)
針葉重量を計算していたので安心した.
そして可塑性有無による変化は,
まあ,
発注者の意向にそった計算結果にはなっている.
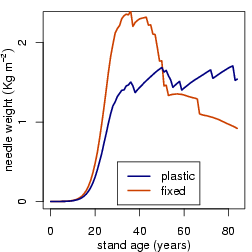
[可塑性なければ自滅]
個体群の針葉重量の変化.
シュート形成のルールが
どのような状況でも不変な樹木は
キビしい個体間競争を生きのびた樹木であっても
年齢とともにじりじりと衰退している
(非同化部の構築・維持が苦しいため).
いっぽう,
枝先の水ポテンシャルをシグナルとして利用して
可塑的にシュート形成する樹木は葉量を維持・拡大できる.
-
めんどーな講座雑用発生.
「避難経路にいたる廊下は 1.6m の幅を確保し,
じゃまになるロッカーなどはすぐに撤去せよ」
なるとーとつなるお達しがでてしまった.
ありていに言って現時点の A 棟 8F に関してはこのお達しは
ことさらに無意味である.
というのも,
非常階段出入口は厚さ 2m ばかりの積雪で埋めつくされており,
そこにいたる廊下からロッカーのたぐいを取り除いたところで
依然として脱出不可能であることにかわりないからだ.
-
しかし,
まあ,
なんでも会計掛に申告だせば不要備品を捨ててくれるらしいんで,
その対応にとりかかる.
-
苫小牧から直径成長でもなければ parasitoid
でもない質問メイルがたてつづけに二発
……
R
の
glm() に関するやつだ.
おたがい R を使ってて便利なのはこういうときで,
相手のデータがなくてもメイルに書かれた状況から,
「たぶんこういうデータを使っているんだろう」
と乱数で「擬似データ」を手もとでささっと組み立てて,
どういう状況におちいってるかを解析できるからだ.
この手法でだいたい問題点がわかったので返信してみる.
-
Dell 機で parasitoid の MPLE randomization
計算やりなおしさせるよーにしてから
2020 研究室発.
2030 帰宅.
晩飯.
ちかごろうんどう不足ぎみだ.
-
自宅から A 棟 8F 闇ネットに ssh で入りこむ.
上記 randomization 計算はモデル簡単化のおかげで
1.8 時間ほどで終了.
ぱいぷ樹木に関して,
念のため計算を実行させる.
これも 4 時間ほどで終了するだろう.
-
[今日の運動]
-
腹筋運動 30 ×
3 回.
腕立ふせ 5 ×
3 回.
-
[今日の食卓]
- 朝 (0740):
米麦 0.7 合.
ネギ・マイタケ・卵の炒めもの.
- 昼 (1420):
研究室お茶部屋.
米麦 0.7 合.
ダイコン・ハクサイ・海藻・豆腐・さばぶしの味噌汁.
- 晩 (2200):
米麦 1.0 合.
ネギ・マイタケ・卵の炒めもの.
ワカメスープ.