sudo apt-get upgrade
したら apache 関連のモジュールが更新されて
……
また CGI プログラムが動かなくなった!
Ubuntu 13.10 apache2 あれこれ更新したら,また CGI あれこれが動かなくなり 数時間の悪戦苦闘……ふと思いついて apt-get remove apache2-suexec-custom したら,まったく問題なく動作したので椅子から転げおちそうになった……
— 久保拓弥 (@KuboBook) 2014, 3月 25apache2-suexec-custom
というのがいつ入りこんだのか,
自分ではぜんぜん記憶がない
……
まあ,生態学会のふつうの統計ユーザーの場合,こういう理解なのではないでしょうか.
- 検定は「真のモデル」を決める方法のひとつであり,まちがえる確率は 5% (あるいは P)
- モデル選択もほとんど同じ目的の手法だが,まちがえる確率は 15% になる
- モデル選択のほうが新しい手法なのにまちがえる確率が高くて意外だ
検定に関して,帰無仮説が棄却される場合に限定したとしても,P < 0.05 なら対立仮説が「真のモデル」と断定してよいと考えているユーザーが 多いのではないでしょうか. 猛者になると P > 0.05 なら帰無仮説が真のモデルと断定しそうですね.
ハナシが少しずれますが,この背景にあるのは P とか AIC といった一個の推定値を見て (つまり統計学的手法の理解する努力の最小化をはかりつつ), 強力無比な結論を断定的に主張してみたい (主張の最強力化),といった考えかたなのかもしれません.
さてさて……粕谷さんは AIC の説明をするときに「予測の最適化」と説明されることが多く, これはまったく正しいと思うのですが, じつは聞いても理解できない人が多数派なのかもしれません. 私は「統計モデルを使った予測」という考えかたは,生態学な人たちのあいだで あまり明確に認知されていないと考えています. 周りの院生たちを見ても,推定値を組み合わせて予測を示せるような人はほとんどいません.
「よくわかってない」に関していえば,予測だけでなく,そもそも GLM の係数の推定値についても, あまりよくわかっていない人が多いように見うけられます.たとえば R の summary(glm(...)) の係数 table をそのままはりつけてポスター発表する人がたくさんいますが, この table の中で「説明変数名とアスタリスク *」だけが「理解」されいている場合が多いように思います. 効果の推定値が何を意味するのか,あるいは SE の大きさはどう考慮すべきか …… といったことが読み取れないのであれば,「予測」がぜんぜんわからなくても不思議ではありません. とうぜん AIC と予測の関係もわかりません.
AIC 誤用を指摘する粕谷さん発表の「意外だ」うけとりの背景について, いろいろと考えているわけですが, 上記 1, 2, 3 的な発想のもとで「まちがえる確率」なるものが 15% であることが意外だという人がいたら,私ならば「AIC と説明変数のセット」 だけを見て,統計モデルの予測の良さを検討するのは危ないので,パラメーターの推定値や SE もあわせてよく見なさい,という方向から説明するかもしれません.
たとえば,発表中で示された y ~ rnorm(1000, mean = 0) で説明変数 x の係数はゼロとしている乱数実験で, AIC による「誤選択」は 10000 回のうち約 1500 回,とだけ述べるのはやや不親切で, 「説明変数 x いれたモデル」 1500 個の x の係数はどういう値だったのかを示せば, 予測における「推定値の不確かさ」の効果なども示せるような説明になるかもしれません.
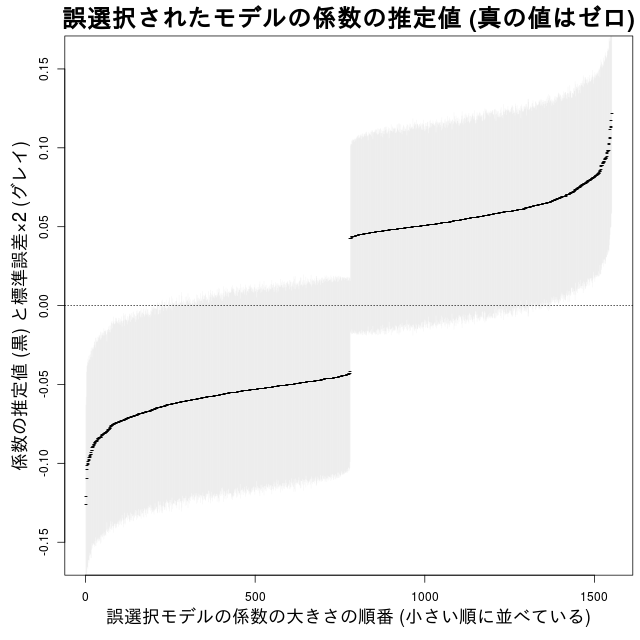
ひとつの例として,粕谷さんと同じ条件で実験してみると,誤選択されたモデル, つまり「説明変数 x いれたモデル」の x の係数の推定値とプラスマイナス 2 SEの range を図示すると,
このようになることから,余計な説明変数 x をもつ誤選択モデルであっても, この 2 SE 区間にゼロを含む場合が多いので,「予測において x の効果を考慮するのが良い」 と断定するのは難しくなる (あるいは統計モデルは x という説明変数を含むが,これは予測 にあまり影響を与えない可能性がある) …… といった方向で考える人が増えるようになるかもしれません.
AIC の誤用を説明するときに,AIC の値の大小だけを検討して, 誤選択された統計モデルの推定値はどのようなものになるかを示さないのは, ちょっとわかりづらいのでは……と感じたので,ちょっと自分で試行錯誤しながら 「つけたしの説明」の一例を作ってみた, というかんじです.