ps.prev ps.curr mb6 mb7 mb8
1998 29.32520 28.47498 0.9027496 3.597631 5.870321
1999 28.47498 27.47836 1.5465118 2.963915 5.808647
2000 27.47836 27.18689 1.6203430 5.217963 7.027452
2001 27.18689 30.19222 0.5989664 6.524714 4.136431
2002 30.19222 27.40877 0.2516792 2.378106 5.018846
2003 27.40877 29.60587 1.4684730 1.525402 3.319788
2004 29.60587 0.00000 0.7690110 0.000000 0.000000
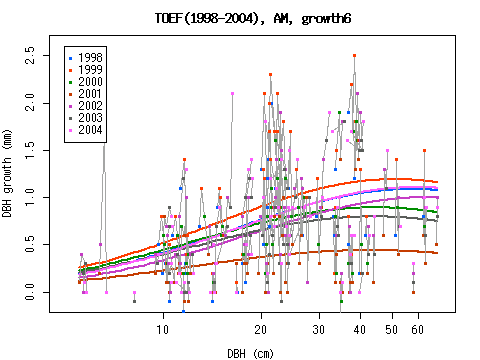
当年の天気に依存する代謝気象値は
おそらく成長量の集団平均によく対応してるように見えるんだが,
昨年の天気で決まる光合成気象値のほうは必ずしも単純でない
……
glm.nb(growth6 ~ ps.prev + mb6)
すればいいだけじゃないか.
いや,
厳密には glm.nb()
で評価できる負の二項分布モデルとはちょっとズレてるわけだが
(しかし glm.nb() で十分かもしれん,
というのは検討の余地アリ).
この準備段階にあたる序列化計算のためだけに,
おそらく 1458 気象値セットならば 10 分以上を費すだろーけど,
80 時間に比べればぜんぜんたいしたことないわけで.