|
昼ゼミ(最近の研究紹介) 980715
久保拓弥 (北大・地環研・地域生態)
C++ とPerl などを使った個体指向データ解析
ランダム化統計学・最尤推定・個体ベース動態モデル
- 北大に来てからいろいろと新しいデータ解析のスキルを習得できた.
スクリプト言語`Perl' などによるテキスト処理は,これまで「手作業」
でなされていたデータ処理の効率化に有用である.
またコンパイラ言語`C++' によるオブジェクト指向モデリングによって,
「もともとのデータ構造」によく対応したモデリングが可能になりそうだ.
- 今回は,最近取り組んでいる
「無作為化による空間統計学」
「テキスト処理と非線型あてはめによるデータ解析」
「オブジェクト指向と個体ベースモデル」について
簡単に紹介する.
- 今回紹介する計算のためのプログラムはUNIX ワークステーション上にあり
誰でもネットワークを経由してプログラムを利用できる.
無作為化による空間統計学
これまでの生態学の空間統計学で主流だったのは「区画法」である.
「区画法」を用いれば計算量は少なくてすむ.
しかしこの手法では設定した区画の大きさより細かい空間統計量を
知ることはできない.また,区画の数が少ないときには「わくの置き方」に
依存して結果が変わる.
近年,生物の位置情報も離散値ではなく(準)連続値で取られることが多くなった.
そこで「可変クランプ法」を用いた連続空間上のデータの分布様式解析
プログラムを試作してみた.
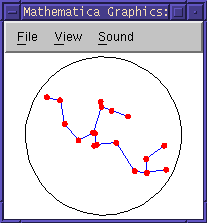
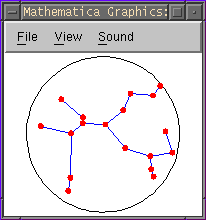
左が札幌市の救急病院(17点)の分布(大田さん入力)であり,
右は点を17個ランダムに配置したものである.
可変クランプ法では点と点をつなぐ線分は「枝」と呼ばれる.
「枝」はあるクランプ距離を設定したときに,
調査空間上のできるだけ多くの点をつなぎ,かつその接続距離が最小になる
ものと定義されている(上の図参照).
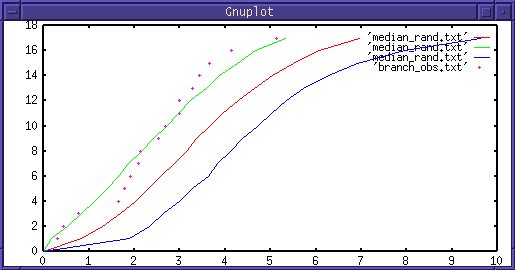
この方法はクランプ距離と枝の数の関係を調べることで,
調査空間上の点の分布様式を特定する.
たとえば点が集中分布していれば,短いクランプ距離で枝数が急に増えるだろう.
また規則分布している場合には,ある特定の距離になったときに急にクランプ数
が増える.
テキスト処理と非線型あてはめによるデータ解析
データ解析というと「表計算プログラムを起動して,
マウスで切り貼りしてという「手作業」を連想するかもしれない.
しかし,この部分を省力化・自動化することで新しいモデリング
の道が開ける……かもしれない.
少なくともやり直しの手間は省けるので「モデルをちょっと変えて
パラメータ推定をやり直したい」というときには便利である.
もちろん複雑な付帯条件をつけた解析なんかも簡単にできる.
[小川群落保護林毎木データの解析例]
もともとのデータは……
0 10 3077 32 95.0 95.30 95.90 96.0 0
0 10 3078 14 26.10 26.80 28.0 28.90 0
0 10 3079 14 17.90 18.20 18.30 18.40 0
0 11 3080 10 72.10 71.40 71.50 70.60 0
0 12 14062 2 27.40 27.50 28.20 28.10 0
......
こんな感じ(じつは上のテキストファイルはすでにかなりテキスト処理が
なされたあとの状態なのだが……).
たとえばこの森林のD-H 関係を知りたいとする.
このテキストファイルをテキスト処理用
プログラムに通すと(プログラムはPerl やMathematica で記述されている),
0 8. 16.6 144.1 8. ACP
1. 10. 23.2 175.8 67. ZZZ
1. 19. 20.1 76.9 24. ACT
1. 27. 8.7 32.6 24. ACT
1. 33. 23.4 141.3 4. CSC
......
といった感じで必要な部分だけを切りだし,
再配列・文字記号の置換などがキーボードからの命令でなされる.このように
して入力ファイルを(マウスで切り貼りなどせずに)準備したら,
あとは「D-H パラメータ推定用非線型あてはめプログラム」に放り込めば
数秒で全樹種のパラメータが得られる.
1.824 0.820 50.102 9 ACM 31 0.513 253
0.880 1.292 23.359 8 ACP 30 0.955 101
0.545 1.602 21.530 17 ACR 31 0.516 139
1.036 1.174 27.198 20 ACS 28 0.675 126
0.752 1.260 21.802 24 ACT 30 0.776 146
......
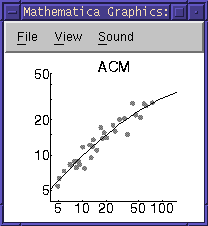
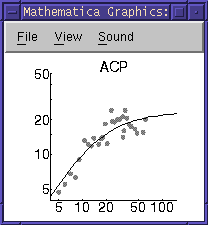
上のプログラムは一部修正するだけでどんな形の関数のあてはめてにも
利用できる.
オブジェクト指向と個体ベースモデル
森林群集動態のデータは毎木単位であることが多い.
そのようなデータ構造によく対応している毎木モデル(個体ベースモデル)
の挙動を調べてみたくなる.
個体ベースモデルを作るにあたって,科学技術計算分野でよく用いられてきた
FORTRAN やC はちょっと不便なところがある.ちょっと技術的な話になるが,
- 動的なメモリの確保が面倒もしくは不可能.
- つかえるデータ「型」が限られている.
- データとその処理がばらばらに分離されている.
……といったことが挙げられる.この不便を克服するのがオブジェクト指向
言語(C++など)である.
具体的に個体ベースモデルのデータ構造を検討してみよう.
もしFORTRAN で森林動態の個体ベースモデルを作ろうと思ったら,
かなり悲惨なことになる.「樹木1 の直径はDBH[1] に格納,高さはH[1] に
格納,現在生きているかどうかはSUV[1] に格納……」という感じで,
やたらと配列を用意しなくてはならない
(しかもいくつぐらい用意したらよいのか事前にはわからない).
プログラムのあちこちに散らばっている変数と各個体の対応関係に
たいへんな注意を払わなければならない
(下手をすると個体間でDBH を「交換」するようなバグも発生しかねない).
C++ ではプログラム製作者が任意のデータ型(「クラス」)を作ることができる.
例えば,Tree というクラスを作ったとしよう.
開発者はTree の設計を自由に決めることができる.
たとえば……「Tree はプログラム中で一本の幹として振る舞う.
Tree のもっている属性はDBH・高さ・年齢などの変数としてあらわされる.
この変数は各個体が『自分自身で操作する』……」.
クラスはその属性(の変数や定数)の扱い方についてあらかじめ指示しておくので,
プログラムが動かすときにはそれぞれのTree に「成長しろ」とか
「来年までに死ぬ確率を算出しろ」とか要求を出すだけで,
各Tree は自分の持っているパラメータや周囲の状況に応じて要求された仕事を
処理する.
このような「かしこい」データ型(あるデータ型に基づいて生成される
個々のデータは「オブジェクト」と呼ばれる)を準備したら,
次に重要になるのは全体の「データ構造」についてよく考えなければならない.
小川群落保護林のシミュレータではこのようなデータ構造を採用している.
個々の樹木Tree のひとつ上にある構造はPatch とよばれるオブジェクトで
ある.これは毎木データの5m コドラートに対応している.個々のPatch は
任意の数のTree を持つことができる.
Patch1 = {Tree1, Tree2, Tree3, Tree4};
Patch2 = {Tree13, Tree14};
Patch3 = {Tree78, Tree79, Tree80};
このような構造を実現するために個々のPatch は「連結線形リスト」と
呼ばれるデータ構造を持っている.
このシミュレータのために開発した線形リストクラスは柔軟かつ高機能に
なっており,各Patch に「自分の持っているTree を大きい順に並べ替えろ」と
いった命令を出すことができる.Patch の上位構造はForest と呼ばれるクラス
である.Forest は,
Forest {{Patch1, Patch2, Patch3, ...},
{Patch11, Patch 12, Patch13,...},
...}
……といった配列型のデータ構造となっていて,60×40 のコドラートをもつ
小川群落保護林のデータ構造と一致するようになっている.

|