—— 生態学の調査データ管理をあれこれ考えてみる (1) ——
トチノキ種子データ解析 を一緒にやらせていただいてる 星崎さん (秋田県立大) から 調査データを計算機でどうやって管理・操作するのが よろしかろうか, という主旨の質問のメイルいただいた. そもそもコトの発端は 「種子の移動分散消長に関する こんな複雑な構造のデータを E*cel なんかに入れるのは呪われてますよ」 というような私の放言である. 返事書いてるうちにどんどん長くなってしまったのと, この問題が一定の一般性を有しているように思えたので, 返信は止めて ここ「自由帳」上の HTML ファイルとして まとめてみた次第である.
> さて、懸案?のexcel問題ですが、ああいうデータ構造の場合って、どんな > 風に入力しておけば後々やりやすかったんでしょうか?
うう, 野外調査してる人たちに文句つけるときは 「E*cel でデータ入力・整理なんてダメダメ, 破綻するにきまってますよ, ひひひ」 とか 揶揄してればよかったんですが …… 自分ではデータ入力しない私としては 「じゃ, 対策は ?」 と聞かれましても 答えに窮するわけです. 「自分ではこういう工夫してます」 という試行錯誤の成果を示せないんで.
しかし, このまますごすごと撤退するのもナンなので, 「せめて E*cel 使うと何がイケなくて, それよりマシそうな何かを提案できないか」 と愚考しなおしてみました.
問題はふたつに大別されるんでしょうか. おそらく本来はこれらは独立してるはずなんですが ……
ということになるかと思います. 前者は 「何を測定するか ? どういう構造でそれを記録するか ?」 ということです. つまり 計算機が無いような状況でも考えるべき問題です. 一方で, 後者は 「計算機のソフトウェアを使って どうやってデータを入力して保守して操作するか ?」 という問題でしょう.
この二つの問題を すぱっと明確に分離して論じることができれば 話はもっと簡単なのでしょうけど …… 私自身やや混同しているところあるかもしれません. さらに,E*cel を評したりすると ますますこれらの問題が混同しそうです.
[Gnumeric] Linux 上で動作する E*celian もどき
ともかく話を無理矢理先に進めることにして …… 例えば 「M$-E*cel のスプレッドシートだのブック形式だのに 片っ端からデータをいれる」 という (多くの生態学者が好んで用いる) 手法について, この分類を適用してみます. まず E*cel (およびそれと似たようなスプレッドシート操作ソフトウェア) によって引き起こされるデータ構造問題は ……
となります. このあたりの問題点および 「データ構造とレイアウト混同問題」 については, 私の駄文などより非常にうまい解説をネット上で見つけたんで, よろしければそちらを見て下さい.
http://member.nifty.ne.jp/maebashi/essay/excel.html
(前橋和弥氏の「表計算ソフトって」)
さて, データ構造問題もさりながら, それと連関しつつ データベイス問題で良からぬことが 生じてしまう …… これが E*cel 使ってデータ入力・操作するときの 問題ではないでしょうか.
E*cel 使ってる人から渡された 多くのデータファイルを 使わせていただいた経験から憶測しますと, 次のような問題点があるのではないかと思います.
ものの本によりますと,近ごろのデータベイスに おいて基本として重視されているのは,
ということらしいです. E*cel をデータベイスとするデータ管理では, 上の三項のどれも成立しそうにありません.
データ共有化は我々が論じているような 「個人で管理して個人で操作する」 規模のデータベイスにはあまり関係ありません. しかし LTER のように 多くの人が係わるプロジェクトでは重要になってくるでしょう (蛇足: しかしマレイシア Pasoh の 50ha Plot のデータが E*cel で管理されている, というウソのような恐ろしい怪談を聞いたことあります).
データベイスの問題は置いといて, とりあえずデータ構造についてだけ, ちょっと考えてみましょう.
E*cel なソフトウェアを使うと, あらゆるデータが何もかも このような二次元配列に格納されてしまいます.
| 0 | 1 | 2 | |
| A | A0 | A1 | A2 |
| B | B0 | B1 | B2 |
このデータをツリー構造で表現してみると, こういうふうになります.
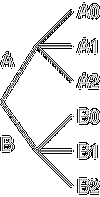
「そろった」ツリー
見ればわかるとおり, このツリーの特徴は,
ということになります. 後者の「分岐から出る枝の数」うんぬんというのは, たとえば上の図ですと, 第二の階層にある二つの分岐から出ている枝の数は どちらも 3 個 (つまり配列の列の数), ということです. この制約を満たすツリーを 仮に「そろった」ツリーと呼ぶことにして, 満たさないものを「ふぞろい」と呼ぶことにしましょうか.
直観的にわかるように, どんな二次元配列もかならず「そろった」ツリーを作りますし, 逆に「そろった」ツリーを二次元配列に変換することも可能です.
つまり二次元配列とは, 「そろった」ツリーの特徴である 二つの制約を常に押しつけられる データ構造とも言えます.
なんでもかんでも E*cel に放りこむ人たちは, この「そろった」ツリーでどんなデータでも 表現してみせる, そーいう覚悟を決めておられるようです. そのために 「そろった」ツリーの制約の中で 許されることといったら, 二つある階層それぞれの分岐から出る枝の数を増やしてやる, ということでしょう (ブック形式というのは三次元配列, というふうに見なせますんで, 三階層の「そろった」ツリーということになります …… 違いは階層の数だけ).
しかしですよ …… 元の表の ``A, B'' ってのが例えば 「個体」を表していて, ``0, 1, 2'' ってのが観測年度だとしますよ. そうすると ``A0'' ってのが 個体 A の最初の年の観測内容 …… とかいうふうになりますと, 個体ごと・年ごとに ばらばらなデータ取られたりするかもしれない ではありませんか.
例えば, 「動かない生き物だから位置は最初だけ記録すればよい」 とか 「×年目で初めて見つかる」 とか 「特別な event があったのでそれを詳しく記録」 とか. そういったことを取り入れて ツリー構造で表現すると, こういうふうに.
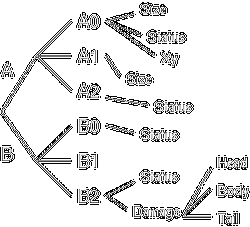
「ふぞろい」なツリー
ツリーの形が「ふぞろい」になります. で, この「ふぞろい」なツリーは もはや二次元あるいは三次元の配列では表現できなくなります.
いやもちろん, それなしでは生きていけないほど E*cel を愛してしまったヒトたちが, (前節で指摘しましたように) あちこち空白ばかりの すかすかな (粗な) 二次元配列を作ったりして, 複雑な構造をもつデータをそこに押し込めようとする, ということは知っております. 空欄をいくつ作ってもかまわない, ということであれば, たしかに たいていのデータは二次元上に射影できるんでしょう. それは否定しません. しかしそのような巨大な配列は おそらく操作しづらいのではないでしょうか. とくに「目で見て手で動かす」ことがキホンな E*cel では ……
じゃ, そういう奇怪な手法を用いないで, 「ふぞろい」なツリーをファイルに格納するにはどうしたらよいか ? 最良の解なのかどうか 自信はもてないんですけれど, よく使われているのは 階層構造をそのまま列挙するような書式です. 上の図はこういうふうに書き下すことできます (あくまでも一例, です).
BEGIN Individual "A"
BEGIN Year 0
Size 1.2 3.7 2.5
Xy 99.9 237.6
Status "生残"
END Year 0
BEGIN Year 1
Size 1.4 3.5 2.5
END Year 1
BEGIN Year 2
Status "消失"
END Year 2
END Individual "A"
BEGIN Individual "B"
BEGIN Year 0
Status "消失"
END Year 0
BEGIN Year 1
END Year 1
BEGIN Year 2
BEGIN Damage
Head "残存"
Body "残存"
Tail "除去"
END Damage
END Year 2
END Individual "B"
|
このように BEGIN-END を何重にも重ねることで, 階層構造をそれほど無理なく表現することができます. インデント (行頭から始まるタブ) が入ってますけど, それは「見てくれ」を整えているだけで, データ構造には何の関係もありません. あくまでも BEGIN と END (そしてこの例では改行) だけで, ややこしい階層構造を表現しています.
上で例として示してるのは, 意味不明な架空のデータにすぎないものです. しかしながら このデータ構造はあちこちで 実用に耐えるものとして頻繁に使われています.
たとえば私が下請けで作った PipeTree というシミュレイターでは, 樹木の各部の属性を記録するために このような階層構造の書式を採用しています. シミュレイターは以下のようなファイルを読み込み, これと同一の書式で結果を出力することができます.
BEGIN FOREST 0
TreeNumber 1
MaxHeight 1.00e+01
ForestCenter 0.00e+00 0.00e+00 0.00e+00
BEGIN TREE 0
Species ZZZ
Pipes 1
Skeltons 1
Height-Area 1.00e+01 1.00e-01
Root 0.00000e+00 0.00000e+00 0.00000e+00
BEGIN TRUNK 2
Height-Area 0.00e+00 1.00e-01
Height-Area 1.00e+01 1.00e-01
END TRUNK 2
BEGIN DEADTRUNK 0
END DEADTRUNK 0
BEGIN SKELTON 1
Root 0.00e+00 0.00e+00 0.00e+00
Term 0.00e+00 0.00e+00 1.00e+01
END SKELTON 1
BEGIN PIPE 0
Status alive
Form vertical
Order 0
ParentId -1
Age 0
AliveArea 1.00000e-01
DeadArea 0.00000e+00
Height 1.00000e+01
Length 1.00000e+01
Assimilation 2.92871e+00
Storage 2.92871e+00
RelativeTermXyz 0.00000e+00 0.00000e+00 1.00000e+01
TermPipelet 0.00000e+00 1.57080e+00 1.00000e+01
FoliageArea 4.00e+01
BEGIN FOLIAGE 0
Edge 0.00e+00 0.00e+00 1.00e+01
Edge 1.90e+00 -5.86e+00 9.61e+00
Edge 0.00e+00 -1.03e+01 1.00e+01
Edge -1.90e+00 -5.86e+00 9.61e+00
Edge 0.00e+00 0.00e+00 1.00e+01
Edge -1.90e+00 5.86e+00 9.61e+00
Edge 0.00e+00 1.03e+01 1.00e+01
Edge 1.90e+00 5.86e+00 9.61e+00
OpenSkyFraction 1.00e+00
END FOLIAGE 0
END PIPE 0
END TREE 0
END FOREST 0
|
このように階層構造書式のファイルに 「ふぞろい」なツリーを格納する, というのは頻繁に使われている技法です. 何とならば, いま読んでいただいている文書は HTML という書式にしたがっているんですけれど, これも上と本質的に同じ階層構造で データ (つまりこの駄文の内容と構造) を格納しています. また近ごろでは, この HTML を高機能にした XML という書式で ありとあらゆるデータを表現してみよう, というのが流行しているみたいです.
星崎さんが E*cel に入れられた 「トチノキ種子の移動分散・状態変化」データも
E*cel から取り出されたテキストファイルの一部 (横にすごーく長い)
当方は宗教的偏見もありまして, こういったファイルは Perl で書いたフィルターで 洗浄に洗浄を重ねたあげくに 祈祷を繰り返すことによって「浄化」し, このように
…… と いうふうに変換してから (この変換例では 厳密な階層構造のテイを為してないし, プログラムで変換してるんで冗長度が 不必要に高くなってますけど), ようやく安心して 集計をとったり 状態の変化を数えてみたり 自動作画プログラムに渡したりできたわけです. もとの二次元格子では, とてもとても こういう複雑なモデル を使った解析をやる気になれませんよねえ ……
さて前節で述べてきたことは, データ構造問題に関することだけであります. データを入力したい生態学者にとって より切実かもしれない 「じゃあ, どうやって入力したり管理したりすればいいんだよう」 という データベイス問題については まるっきり回答になっておりません.
最初に書いてますように, 私は「データうちこみ」とか ほとんどやったことないもんで …… えーと, やったことあるのは …… 鳥の分子系統樹と BCI 2 万格子点の樹冠高だけ, かな. どちらも Sun Workstation の vi (テキストエディター) で入力してました …… ははは. ただし入力後は 点検プログラムをいくつも作って 間違い探しにはかなり尽力しました.
北大の大学院生の皆様にうかがいますと 「E*cel (みたいなスプレッドシート) だと入力がラク」 という回答が多かったですね. しかしこれも 「リターン押したら次の行に進む」 とか 「前後左右の欄を『目』で見て点検しながら 入力できる」 というぐらい意味の 「ラク」 さであるようです. つまり, そんなにたいしたことではないんじゃ なかろーか, と.
そうですね …… もし 自分で 「入力用プログラム」 作るとしたら (これは技術的にはそんなに難しくありません), ユーザーインターフェイスを工夫して 「目」も点検手法のひとつとして活用できるようにすれば E*cel と同程度の「ラク」さは実現できそう, ということですよね. もちろん入力時の間違い (ありえない数値を入れたりとか, 名前のスペルミス, 「死んだ個体が生き返る」 といった 状態変化の矛盾) を 自動的に検出する仕組みを入れる …… すなわちデータ入力前に データの性質について ある程度わかってないといけないんで, やはりデータとった本人が作るのが良いのでしょう.
いったん入力した 「元データ管理」は 規模 (という語もアイマイな気がしますが) が小さければ自作プログラム, 多くの人とデータ共用したり ネット上で活用すること考えれば, Server 機能のある リレイショナルデータベイス (RDB) …… という選択が 私には無難に思えます. もっとも RDB はまだ使ったことないんです. 高機能なフリーウェアの RDB が出回ってるんで そのうち試してみたいですね …… (使う機会なさそう)
入力したデータに操作に関しては, 「元データ管理データベイス」 で行うべきことと, そこから取り出したデータを操作して あれこれと解析するプログラムは 別々に分離しておいたほうがいいんでしょうね. 測定値も計算値も E*cel の中で ゴチャ混ぜにしてるヒトもよく見かけますが ……
うーん, 結局 「生態学者は自分でプログラム組め」 という いつものプロパガンダで終始するような ……
…… ということで, この駄文は羊頭狗肉なまま オチもつかないまま そろそろ おしまい ……
あ, もちろん E*cel など いつでも根絶可能という 信仰に変わりはありません.